Lecture 2: Region Based Segmentation
Segmentation of images is crucial to our understanding of them. Consequently much effort has been devoted to devising algorithms for this purpose. Since the sixties a variety of techniques have been proposed and tried for segmenting images by identifying regions of some common property. These can be classified into two main classes:
Merging algorithms: in which neighbouring regions are compared and merged if they are close enough in some property.
Splitting Algorithms: in which large non-uniform regions are broken up into smaller areas which may be uniform.
There are algorithms which are a combination of splitting and merging. In all cases some uniformity criterion must be applied to decide if a region should be split, or two regions merged. This criterion is based on some region property which will be defined by the application, and could be one of many measurable image attributes such as mean intensity, colour etc. Uniformity criteria can be defined by setting limits on the measured property, or by using statistical measures, such as standard deviation or variance.
Region Merging
Merging must start from a uniform seed region. Some work has been done in discovering a suitable seed region. One method is to divide the image into 2x2 or 4x4 blocks and check each one. Another is to divide the image into strips, and then subdivide the strips further. In the worst case the seed will be a single pixel. Once a seed has been found, its neighbours are merged until no more neighbouring regions conform to the uniformity criterion. At this point the region is extracted from the image, and a further seed is used to merge another region.
There are some drawbacks which must be noted with this approach. The process is inherently sequential, and if fine detail is required in the segmentation then the computing time will be long. Moreover, since in most cases the merging of two regions will change the value of the property being measured, the resulting area will depend on the search strategy employed among the neighbours, and the seed chosen.
Region Splitting
These algorithms begin from the whole image, and divide it up until each sub region is uniform. The usual criterion for stopping the splitting process is when the properties of a newly split pair do not differ from those of the original region by more than a threshold.
The chief problem with this type of algorithm is the difficulty of deciding where to make the partition. Early algorithms used some regular decomposition methods, and for some classes these are satisfactory, however, in most cases splitting is used as a first stage of a split/merge algorithm.
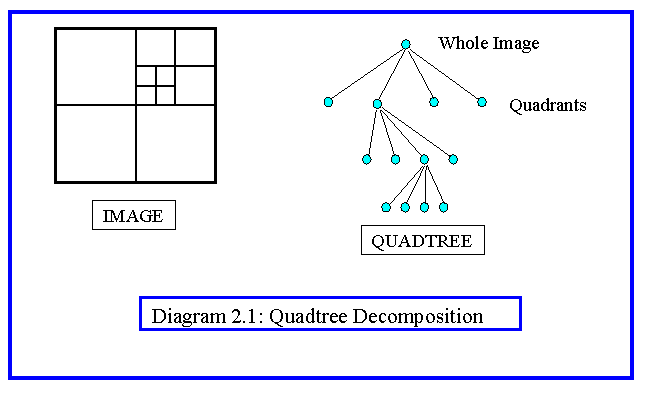
Quadtrees for Region Extraction
An important data structure which is used in split and merge algorithms is the quadtree. Diagram 2.1 shows a quadtree and its relation to the image. Note that in graphics the quadtree is used in a region splitting algorithm (Warnock's Algorithm) which breaks a graphical image down recursively from the root node, which represents the whole image, to the leaf nodes which each represent a coherent region, which can be rendered without further hidden line elimination calculations. The same use is made of quadtrees for vision.
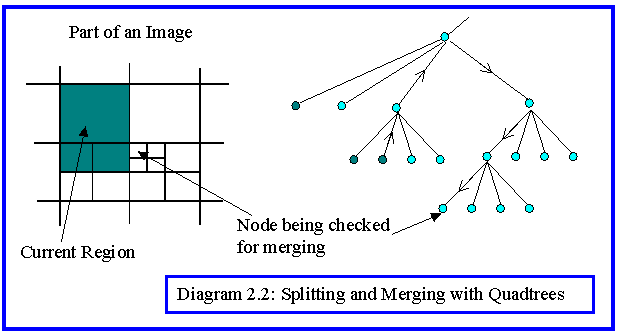
Quadtrees impose one type of regular decomposition onto an image. To complete the segmentation process this must be followed by a merging phase. Thus the problem of finding adjacent neighbours to a given node has been studied (Diagram 2.2). The problem is one of tree search and efficient algorithms have been published.
Splitting and Merging
Characteristic of the split and merge method was the algorithm due to Horwitz and Plavidis. This was based on the use of a segmentation tree, which is normally a quadtree. Each node, say k, in the tree corresponds to a square region of the image, and has stored with it a maximum Mk and minimum mk brightness (or other search property) value.
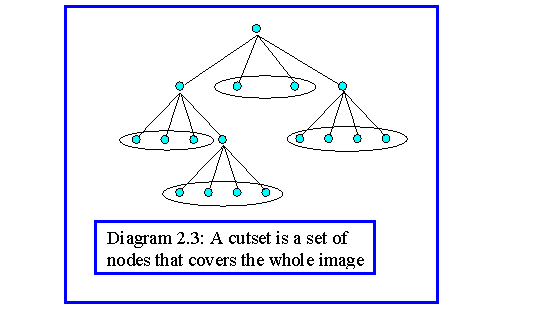
The algorithm starts with a cutset of nodes. This consists of five arrays storing the node properties: {xk,yk,size,Mk,mk}. Note that only the cutset is stored, not the whole tree. For an image of resolution NxN pixels it is theoretically possible that each array requires N2 entries, though, in practical cases, where regions do exist, the requirement is much smaller.
Merging is done by comparing adjacent groups of four nodes with a common parent. If they obey the criterion they are replaced by their parent node. Similarly splitting is done by breaking non uniform nodes into the four children nodes at the lower level (Diagram 2.3). The process is constrained by the tree structure, so, when all the splitting and merging is complete, the final cutset must be grouped into regions. This is essentially a further merging process.
Quadtree Segmentation Algorithms
Although the Horwitz/Plavidis algorithm is essentially based on a quadtree, the whole tree is never stored complete. This is because of the memory requirement. For an nxn image, there would be m levels in the tree where n=2m, and {22(m+1) - 1 }/3 nodes in the tree. Values of n can be up to 512 (m=9) meaning the number of nodes is 349,522. Since each node has at least four pointers (to its children) and one to its parent for efficient processing, the minimum requirement is about 1.5 MBytes. However, with the introduction of cheap VLSI memories, quadtree algorithms have become practical propositions in the eighties.
A naive quadtree algorithm can be constructed by building a quadtree upwards from the image pixels, storing only the mean value of the subtree pixels in each node. To minimise the computation, the mean is computed as the tree is built.
1. Construct a quadtree storing at each node the mean of its four children.
2. Search from the root of the tree to find the node highest in the tree whose mean is in the required range.
3. Use neighbour finding techniques to merge adjacent nodes whose mean is within the desired range.
Although this gives in essence the quadtree method it requires a few modifications before it is a practical algorithm.
The Variance/Average Pyramid
Mean alone gives us no measure of uniformity which is essential in practical cases. Instead we need to use some statistical measure, and it turns out that variance is a convenient, and easy to compute property. Hence at each node in the quadtree we will store both the mean and the variance of the pixels in the subtree.
If the mean of the pixels in a subtree is represented
by:
m = S
I(x,y)/n
Then the variance is defined as:
n = S (I(x,y) - m)2/n = S I(x,y)2/n - m2
This method of computing the variance however is computationally expensive, and instead we need a recursive formulation, similar to the mean computation. The formula is:
nk+1 = (nk1 + nk2 + nk3 + nk4 + mk12 + mk22 + mk32 + mk42)/4 - mk+12
The proof of this formula can be done by induction. Using it the tree can be built without undue overheads. For each node we compute:
Mean 4 additions 1 shift
mean2 1 multiply
variance 9 additions 1 shift
Uniformity Linkage
We can now properly segment an image using the same method as before, but searching in step 2 for the highest node within the required mean and variance range. However, further saving in time can be made by recording the highest uniform node in each subtree as we build the tree. This eliminates the need for a search after the tree is built.
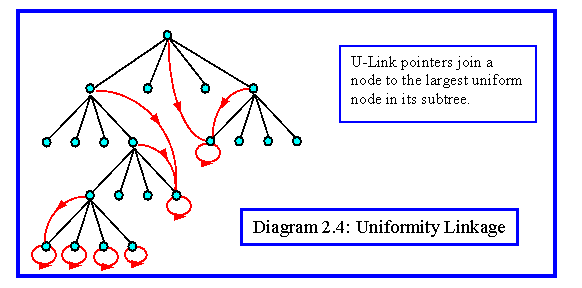
The uniformity is recorded by adding one further pointer to each node in the tree. This is called the u-link. It is computed as follows:
1. If a node is out of range (in variance) and all nodes in its subtree are out of range, its u-link is set to null
2. If a node is in range, set its u-link to point to itself.
3. If a node is out of range, but some nodes in its subtree are in range, set its u-link to point to the highest node in its subtree which is within range.
A tree with some u-links is shown in diagram 2.4. Having built a tree with u-links, segment it into a number of regions. Taking the node pointed to by the root, we use it as a seed and merge its neighbours as before, setting the u-links of each merged nodes to null. We can then extract further regions by moving down the tree and processing similarly any nodes with non null u-links.
Note that most of the work of the algorithm is now in the first step of building the tree. This is advantageous since it is now possible to implement quadtrees on pyramid architectures thus making effective use of parallel processing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}