Lecture 4: Edge point Detection
In the previous lecture we discussed segmenting images on the basis of region properties. An alternative approach is to search for the boundaries of each region of interest. This is a complex process, and is usually broken up into at least two stages: edge point detection and grouping edge points into contours.We will concentrate in this lecture on the question of detecting edge points. The main feature used to determine whether a pixel in an image can be classified as an edge is its intensity gradient. The higher the gradient the more likely we can say it is an edge. Practical systems are limited to the detection of clearly defined edges such as boundaries formed by occluding contours (one dissimilar object covering another) or shadows. It is harder to detect fine surface detail such as texture, or boundaries between similar objects such as sea and sky. A number of methods have been proposed to determine the gradient of an image at a pixel, and most of these use the method of convolution of the image with a filter.
Mathematical Interlude:
Convolution was introduced in the graphics lectures as a technique for anti-aliasing an image and for computing the locus of a B-spline curve or surface. The following section revises the points made in those lectures. Convolution defines a way of combining two functions. In the most general form it is defined as a continuous integral which in one dimension is:
|
¥ |
||
|
C(x) = |
ò |
I(p) f(x-p) dp |
|
-¥ |
or in two dimensions:
|
¥ |
¥ |
||
|
C(x,y) = |
ò |
ò |
I(p,q) f(x-p,y-q) dp dq |
|
-¥ |
-¥ |
The function f in the above equations is usually called a filter. An example of convolution between a function and a filter is given in diagram 4.1. For cases encountered in computer graphics and in computer vision, both the functions f an I are discrete, so, for two dimensions, the convolution integral simplifies to:
|
Xres |
Yres |
||
|
C(x,y) = |
S |
S |
I(p,q) f(x-p,y-q) |
|
p=1 |
q=1 |
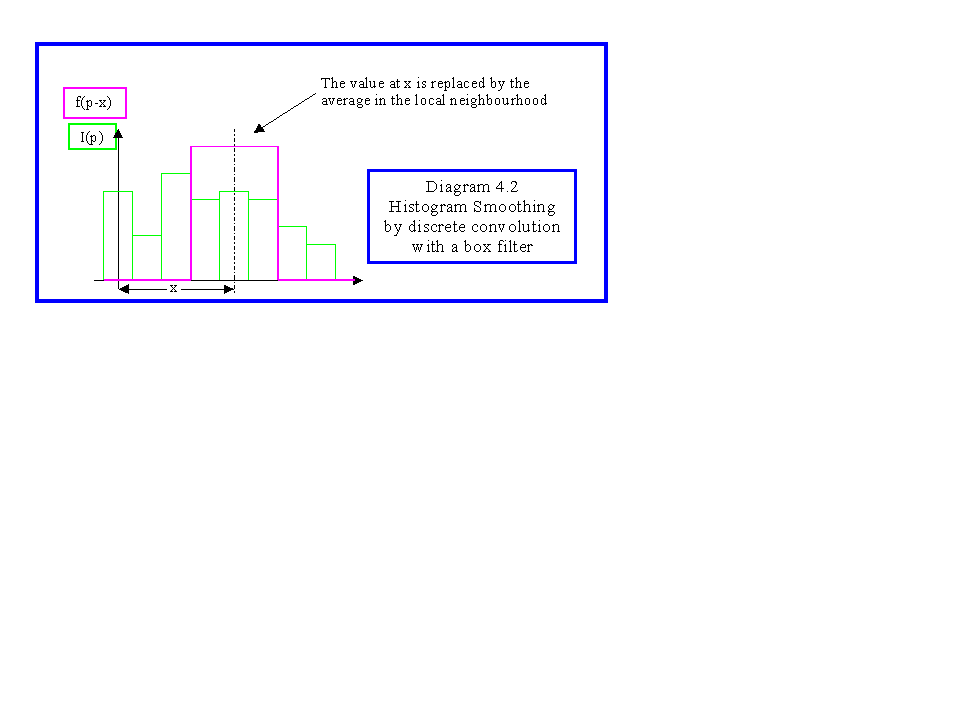
where I(x,y) is the discrete function defining the pixel values, f(u,v) is the filter function, and [1..xres,1..yres] is the range over which I(x,y) is non zero, i.e. the resolution of the picture. The discrete equivalent to the example in diagram 4.1 is shown in diagram 4.2 and is known as histogram smoothing.
The simplest filter function for obtaining a gradient is:
|
f(u,v) = |
1 if v=1 and |u| <= 1 |
|
= |
-1 if v= -1 and |u| <= 1 |
|
= |
0 otherwise |
To give that a geometrical (and hopefully clearer) interpretation, we can present it a tabular format called a mask:
|
u=-1 |
u=0 |
u=1 |
|
| v=1 |
1 |
1 |
1 |
| v=0 |
0 |
0 |
0 |
| v=-1 |
-1 |
-1 |
-1 |
Since the filter falls to zero for all values of |u| and |v| greater than 1, we can compute the convolution at some point [i, j] by letting x=i and y=j and summing the pixels in the surrounding 3 by 3 volume multiplied by the corresponding filter value. Equation 1 reduces to:
| C(i,j) = |
I(i-1,j+1) f(-1,1) |
+ |
I(i,j+1) f(0,1) |
+ |
I(i+1,j+1)f(1,1) |
+ |
|
I(i-1,j) f(-1,0) |
+ |
I(i,j) f(0,0) |
+ |
I(i+1,j) f(-1,0) |
+ |
|
|
I(i-1,j-1) f(-1,-1) |
+ |
I(i,j-1) f(0,-1) |
+ |
I(i+1,j-1) f(1,-1) |
substituting in the values of the filter we get:
C(i,j) = { I(i-1,j+1) - I(i-1,j-1) } + { I(i,j+1) - I(i,j-1) } + { I(i+1,j+1) - I(i+1,j-1) }
Which can be be seen to be an approximation to the gradient in the y direction only. The value computed is the central difference approximation to the first differential averaged over three adjacent pixels. The above mask is one of a class known as the Kirsch operators. They are useful for identifying straight edges of known orientation. The other three 3 by 3 Kirsch operators are:
|
-1 |
0 |
1 |
0 |
1 |
1 | 1 |
1 |
0 |
|
-1 |
0 |
1 |
-1 |
0 |
1 | 1 |
0 |
-1 |
|
-1 |
0 |
1 |
-1 |
-1 |
0 | 0 |
-1 |
-1 |
Clearly, at any pixel we can compute all four and, depending on which operator yields the largest, classify the pixel as belonging to a line either parallel to the Cartesian axes or at 45o to them. In the more general case we are not merely concerned with detecting straight lines, but with curved boundaries. The simplest solution is to compute the gradient from the central difference alone. For the vertical direction, the 3 by 3 mask would be:
| 0 | 1 | 0 |
| 0 | 0 | 0 |
| 0 | -1 | 0 |
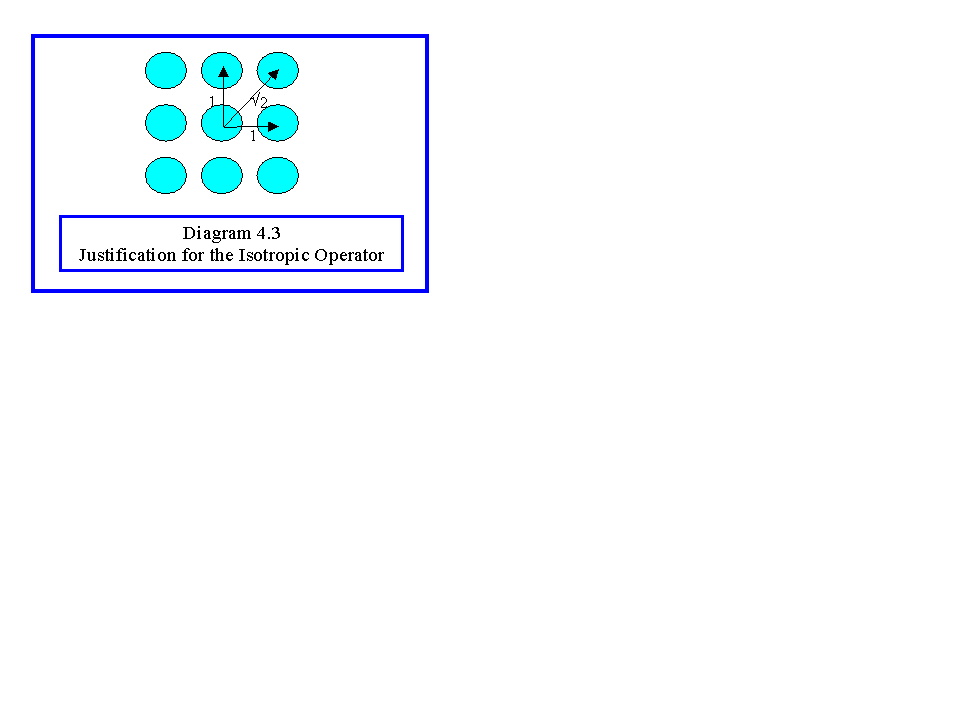
However, this is not normally used since in practice images contain some noise in them due to the recording media and the quantization process. Instead an averaged estimate is computed taking account of the proximity of the neighbours. Diagram 4.3 shows that distances of the eight neighbouring pixels to a pixel where we are computing the gradient. If we weight the Kirsch operators by the inverse of the distance of the pixel, we get for the vertical gradient:
|
1/Ö 2 |
1 |
1/Ö 2 |
|
0 |
0 |
0 |
|
-1/Ö 2 |
-1 |
-1/Ö 2 |
Since we are not concerned about the absolute value of the gradient, we can multiply out the Ö 2 factor to get:
| 1 | Ö 2 | 1 |
| 0 | 0 | 0 |
| -1 | -Ö 2 | -1 |
which is called the isotropic operator, since it is reckoned to give the most accurate estimation of the gradient (gy) in the vertical direction. A similar operator gives the gradient in the horizontal direction (gx):
| -1 | 0 | 1 |
| -Ö 2 | 0 | Ö 2 |
| -1 | 0 | 1 |
Using these two isotropic operators it is possible to compute an absolute gradient at each pixel as:
G = Ö (gx2 + gy2)
Associated with each gradient computed in this way there is a corresponding edge direction given by:
tan q = gy / gx
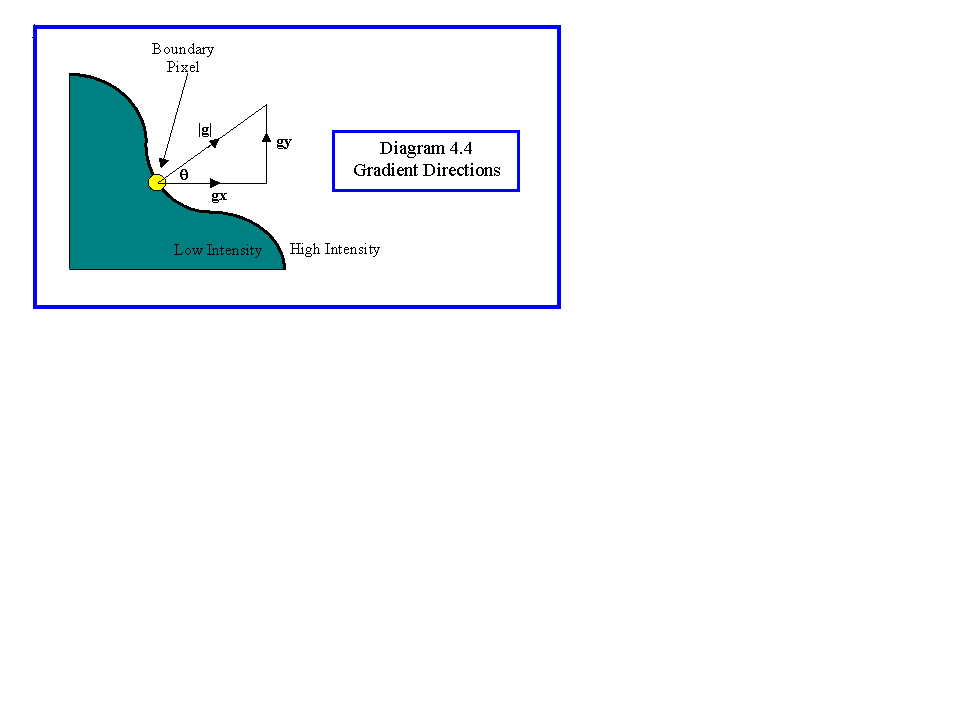
Note that the direction gives the radial direction for any boundary to which the edge point belongs, and not the boundary direction (Diagram 4.4). Although the isotropic operator is normally regarded as being the best estimate, other types of gradient mask are used. For example the Sobel operator is commonly used and is a compromise between accuracy and ease of computation.
| 1 | 2 | 1 |
| 0 | 0 | 0 |
| -1 | -2 | -1 |
There is a corresponding operator for the horizontal gradient, and an absolute gradient and edge direction can be computed as before. The attraction of the Sobel operator is that it can be computed by using shifts and adds only, hence a fast implementation is possible. It is possible to correct the Sobel magnitudes for better directional accuracy. The following formula is used for the first quadrant:
tan q = gy/gx if 0<= gy/gx <=1/3
tan q = (3gx - 11gy - v(112gy2+16gx2 - 64gxgy))/(-7gx-9gy)
if 1/3< gy/gx <=1
Similar formulae may be derived for the other octants.
The Laplacian Operator.
For a function in two dimensions, the Laplacian operator is defined as the sum of the second derivatives in the two dimensions.
Ñ 2 f(x,y) = ¶ 2f / ¶ x2 + ¶ 2f / ¶ y2
This can be computed by the discrete formula based on the second central difference. Taking the simple estimate of the second gradient in the x direction we get:
{ I(i+1,j) - I(i,j) } - { I(i,j) - I(i-1,j) }
{ I(i-1,j) - 2I(i,j) + I(i+1,j) }
There is a corresponding equation for the second derivative in the y direction. Adding these two together we obtain the mask:
| 0 | 1 | 0 |
| 1 | -4 | 1 |
| 0 | 1 | 0 |
Edges are now taken as places where the Laplacian crosses zero between pixels. The Laplacian is rarely used as an edge detector (Marr is the exception) since it gives no information about the direction of the edge.
Gaussians and Gradients
It is useful to note that an image is a scalar function in two dimensions. The first differential is, in contrast a vector function computed using the gradient (or grad) function.:[ ¶ I(x,y)/¶ x, ¶ I(x,y)/¶ y]. The second differential or Laplacian is again a scalar function which is the divergence (div) of the gradient, expressed as a dot product using the differential operators:
[¶ /¶ x,¶ /¶ y]•[ ¶ I(x,y)/¶ x, ¶ I(x,y)/¶ y]
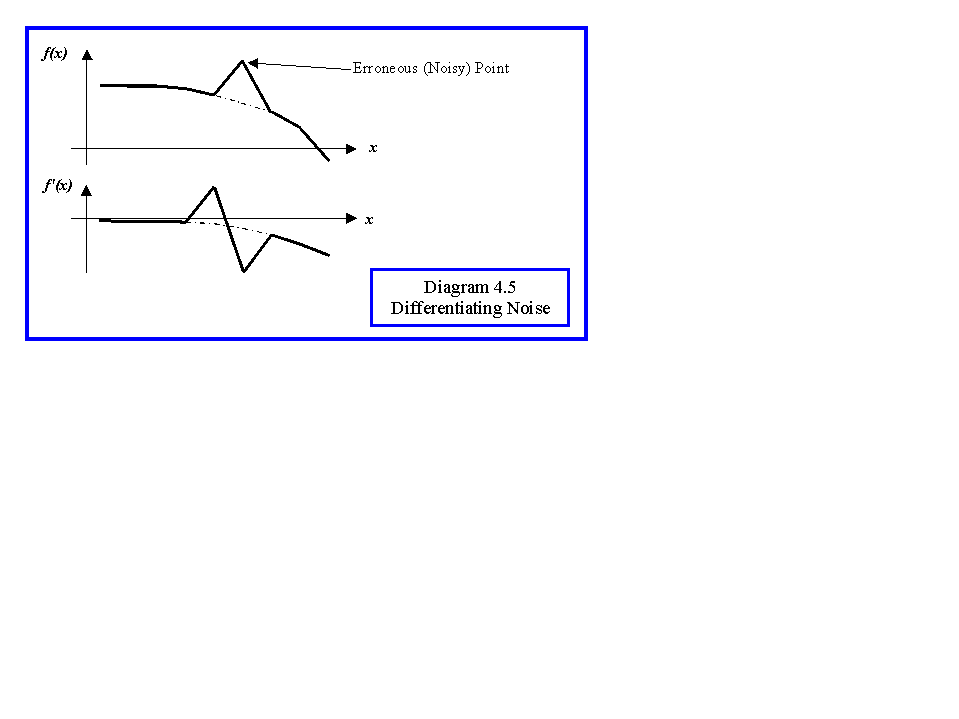
In practical cases there is a problem with noise. This is because any random noise which changes more rapidly than the image features will be amplified by the differentiation process and cause worse errors in the firest and second differentials. Diagram 4.5 shows schematically why this is so. Thus it is common practice to smooth the image to remove high frequency noise before taking the differential. The normal way to smooth the image is by convolution with a Gaussian filter, and the usual approximation is given by the mask:
|
(1/36)´ |
1 |
4 |
1 |
|
4 |
16 |
4 |
|
|
1 |
4 |
1 |
This mask offers both computational efficiency and a close approximation to the true Gaussian. For greater smoothing, bigger masks can be used and these can be computed from the equation of the Gaussian which is: G(x,y) = a exp(-b(x2 + y2)). The constants b is chosen to set the width of the mask, for example for a five by five mask the value of G should fall close to zero when x and y are equal to 5. The constant a should be set such that the mask entries add up to one.
Sometimes it is computationally desirable to combine the operations of smoothing and differentiation. This can be done by building a composite mask which is made up of the differential of the Gaussian.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}