Lecture 17: Modelling for Vision
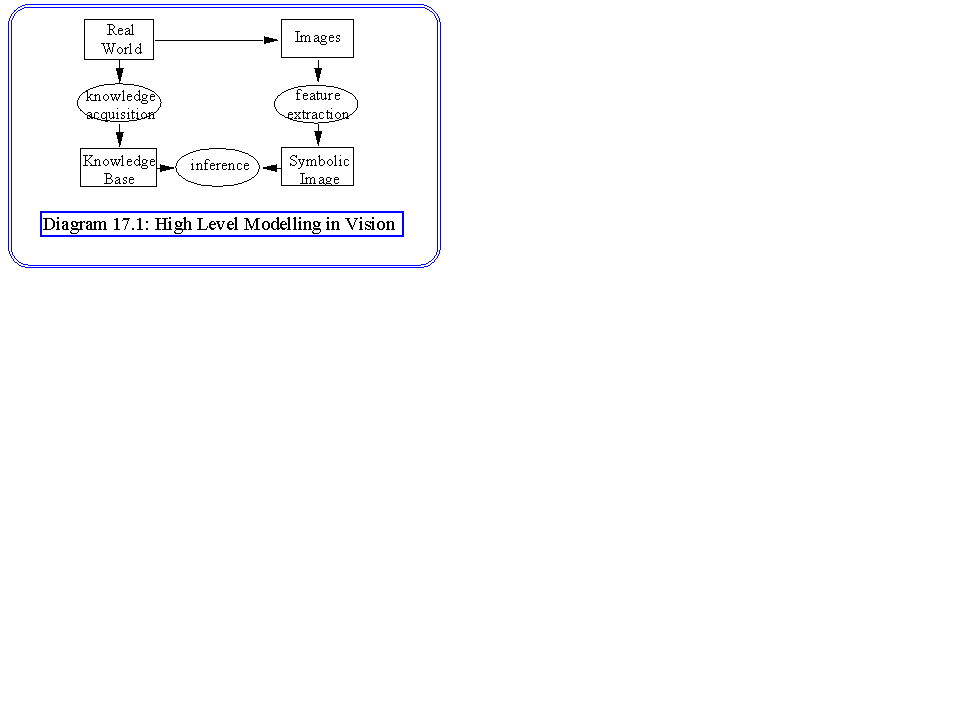
Modelling in the scientific sense is the construction of systems that are analogous in their behaviour to the system being studied. In physical modelling we are interested in determining the behaviour of a system, with a view to exploiting its properties, often for engineering products. In vision however, we are primarily concerned with reconstruction, with a view to measuring some properties, such as blood flow, or making decisions, for example, about the control of a vehicle. Modelling in vision in strongly associated with prior knowledge, and the type of model that is adopted depends on the way in which that knowledge is expressed. A general schema for high level model based vision is shown in diagram 17.1. We will review the modelling methods here.
Geometric Modelling
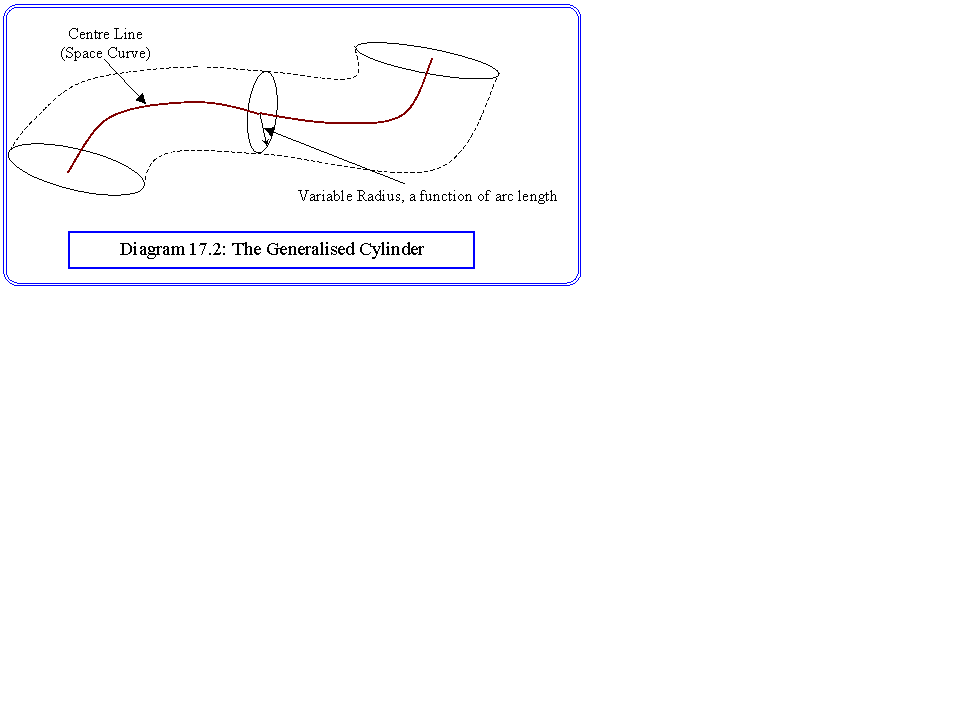
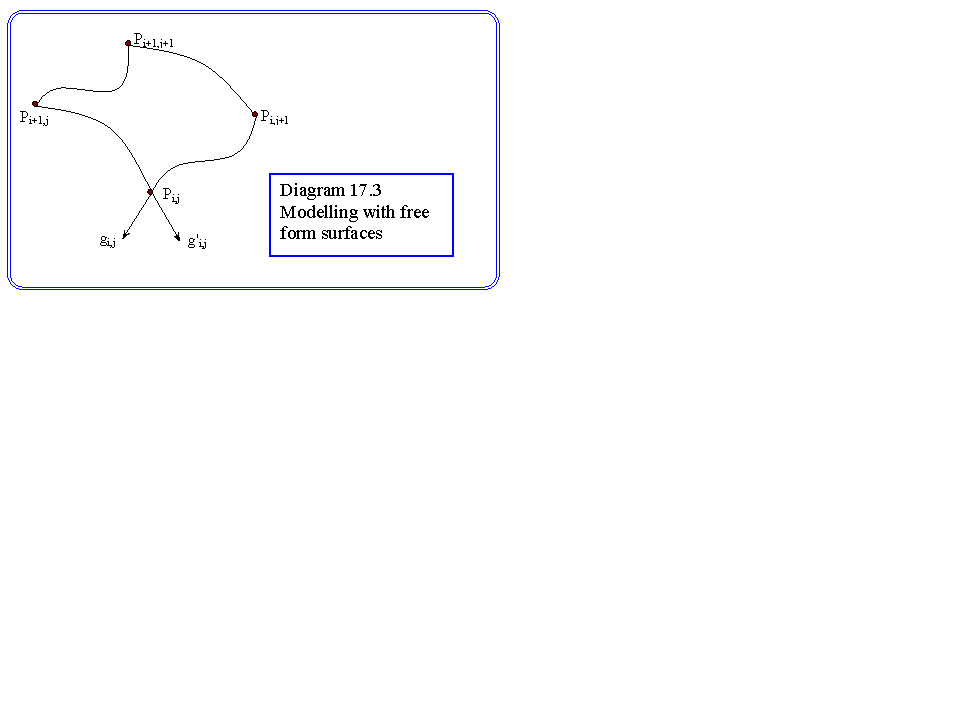
Our prime concern to date has been the extraction of geometric models. In the simplest case these have consisted of point co-ordinates only. Clearly, boundary extraction, which seeks to find two dimensional geometric entities, is an example of this, as is computational stereo and photometric stereo. In a loose sense so also is the work we studied on optical flow, and magnetic resonance reconstruction, though these studies could well be termed kinnematic modelling. Geometric models can be taken one step further, by associating simple shapes with the points identified in the image. Work has also been done in matching known points into higher order surfaces. For example, quadratic or cubic surfaces can be used to model more complex shapes. One example is the generalised cylinder, which is described as a centre line along which a circle of variable radius is swept (diagram 17.2). The use of these types of structure is rather like solid modelling in graphics. We define the cylinder centre line and radius to match as closely as possible to the real object. Unfortunately, we need to make simplifications to represent real objects. A more useful possibility is cubic spline surfaces often termed free form surface modelling. These may be constructed to match a wide variety of shapes. The shape of a cubic patch may be controlled by specifying its edges |(points extracted directly from the data) and the two gradients at each corner. (see Diagram 17.3). The gradients can be set interactively, or by means of techniques such as least squares parameter estimation. The main limitation is that the surfaces must be smooth. This type of modelling can be used very effectively for visualisation purposes, for example in the study of the motion of the heart ventricles. However, the mathematics of cubic surfaces is hard, and even simple problems, such as the intersection between a cubic surface and a sphere pose real difficulties which make them ineffective tools in, for example, real time navigation work. A degenerate form of geometric model is sometimes called iconic modelling. That is instances where we seek to recognise objects by means of templates defined in terms of pixels. Into this class fall the neural pattern recognisers.
Procedural Modelling
In some cases it may be appropriate to express our prior knowledge in terms of a procedure rather than a static structure. Examples of this type of modelling appear where time is involved, for example in navigation systems, though other problems can be expressed in terms of procedures.
Relational Modelling
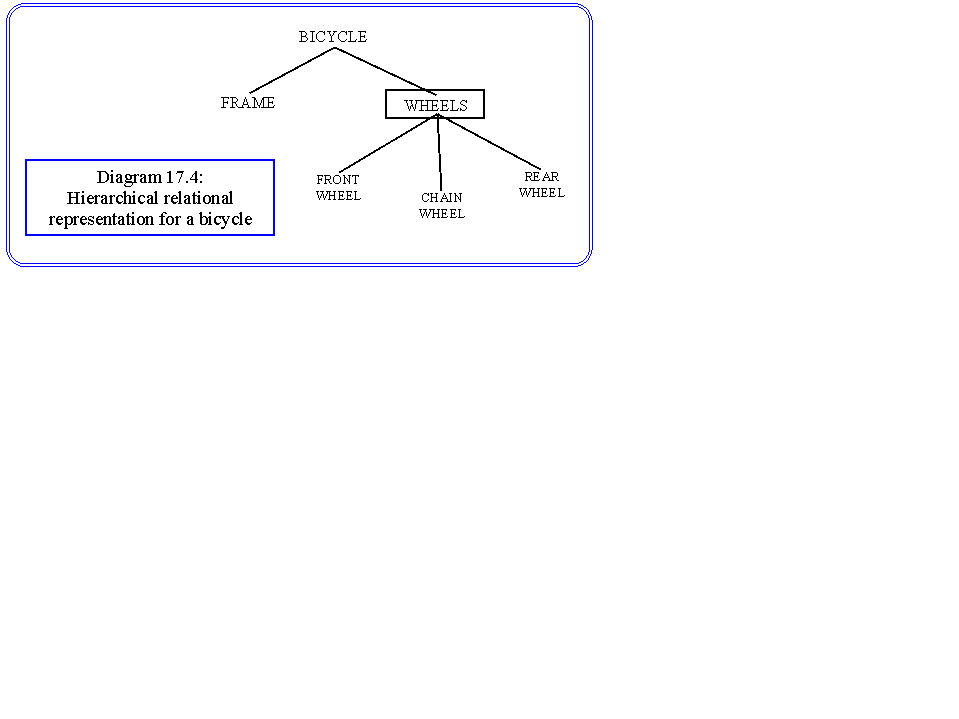
An important area we have not covered to date is relational modelling. Here we are concerned with making assertions about a scene, or about a set of objects, over which we can make generalisations. To illustrate the concepts behind relational modelling, we shall consider the example of a bicycle. We can specify our model at a number of levels of details, depending on the scope of our vision system. In the simplest case we can choose to define the bicycle in terms of sub-objects: Front Wheel, Rear Wheel and Frame. This may be sufficient in many cases, but not if we are to process a domain containing children's scooters. For this we would need to include the sub-objects chain wheel and chain. An hierarchy diagram can be constructed to store this information, an example is given in diagram 17.4.
We can use geometric modelling to make certain extractions from our image. In particular, we can state that the bicycle wheels are circles, and the frame is made up of straight members. So a geometric solution would be to use a Hough transform to extract all the circles, another Hough transform to extract the straight lines, and a template matching process to recognise bicycles. The geometric modelling gives us the ability to compensate for missing information, since it is possible to recognise circles in a Hough Transform, when only part of the boundary is visible. However, this does not give us much scope for variation in bicycle style. The relational structures allow us to define the class of bicycles without specifying the exact geometry.
A number of relations can be stated about our bicycle, which can aid the recognition process. For example, we could make an assertion that both wheels are the same size. This restricts the domain, since penny farthing, and butcher's bicycles are now excluded. Secondly, we can make an assertion about the wheel base. The difference between the centres must be at least twice the wheel diameter, and probably not more than four times the diameter. It is possible therefore to code up a set of rules , which could be used to limit our search of the geometric entities that we find in the image:
if a circle is more than four diameters from its nearest neighbour
then remove it from the image
if a circle is different in diameter from all circles in the image,
then it is not a road wheel.
Further rules can be derived from the connectivity:
if two equal circles are not connected by frame lines,
then they do not form a bicycle
And from the spatial relationships expressing the fact that the front wheel is in front of the frame, and the rear wheel behind. In short, relational modelling allows us to build up a set of rules which can be used to eliminate those entities that could not make up a bicycle from our image.
Semantic Nets
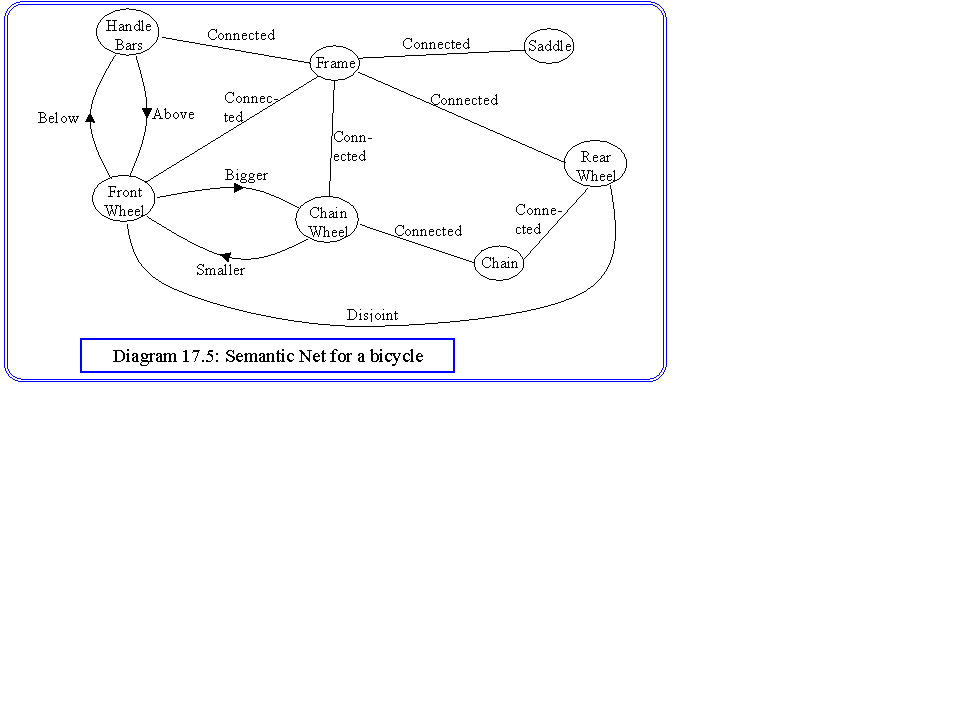
One proposal for expressing relational structures with great generality is semantic networks. These have been used in a general context in AI, and have been proposed for vision. A semantic net is a graph structure, where the nodes represent objects, and the arcs represent relations. Some of these may be directed, and some may be bi-directional. An example, representing our bicycle model is shown in diagram 17.5.
In essence, we want to use our semantic net as a way of guiding our search for objects in a visual scene. Thus, we assume that we have procedures for extracting the objects at the nodes. Thus the nodes in the net contain definitions for geometric, procedural or iconic models. Some observations should be made about the arcs. Firstly, some of the relations are symmetric, hence for the relation 'above', there is a symmetric arc 'below'. Others, such as connected to are bi-directional. Secondly, each relation may have different implied implementations. For example, we use connected to describe the relation of the frame to the front wheel, meaning the connection is carried out at the centre. We have used the same relation name to join the chain to the chain wheel, where the connection is at the circumference.
Inference from semantic nets frequently follows the popular frame concept of Artificial Intelligence. That is to say, we store a generic structure, into which we attempt to match components of the image. Thus, if we can match part of a semantic net, such as the two wheels and the chain wheel, we may conclude that we have found a bicycle, and that some artefact has prevented us from seeing the frame. This concept is appealing in that it seems to match our own experience in reasoning, however, we have noted in the previous paragraph that each arc and node in a semantic net may require its own implementation. Thus, any hope of using semantic nets for general purpose inference systems is over optimistic. For this reason, the main use of semantic nets is in the design of programs which contains relational information.
Production Systems
The problem of matching relations or rules is well studied in artificial intelligence. The typical solution is the use of production system, which can be looked on as a mechanism for coding up semantic nets. It consists of three parts: a data base, a set of rules and an interpreter. The rules can be manipulated in general, and may be given certainty factors which are used by the interpreter. The data base will be a set of facts extracted from the image. For our bicycle these may be the positions of circles, and of the lines which can be matched into a frame. The rules will parameterised relations, which can be built up in an hierarchy. Thus corresponding to the hierarchy diagram we might have:
if (Radius(X) = Radius(Y)) and (Radius(y) <Distance(Centre(X), Centre(Y))<4*Radius(Y))
then Wheelpair(X,Y).
etc.
The interpreter has the task of fitting the parameters into the rules to make deductions, either by forward or backward chaining. There are problems with production systems of which some are:
Non unique matching of rules and facts
Rules become inappropriate with changes of context
The matching process (inference) is computationally very expensive
The data base becomes unduly large for practical systems.
The principle of least commitment can be applied here. It would state that among a choice of rules, one applies the most general. To measure the generality the number of parameters of the rule could be counted.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}