Lecture 20: Bayesian Networks in Vision
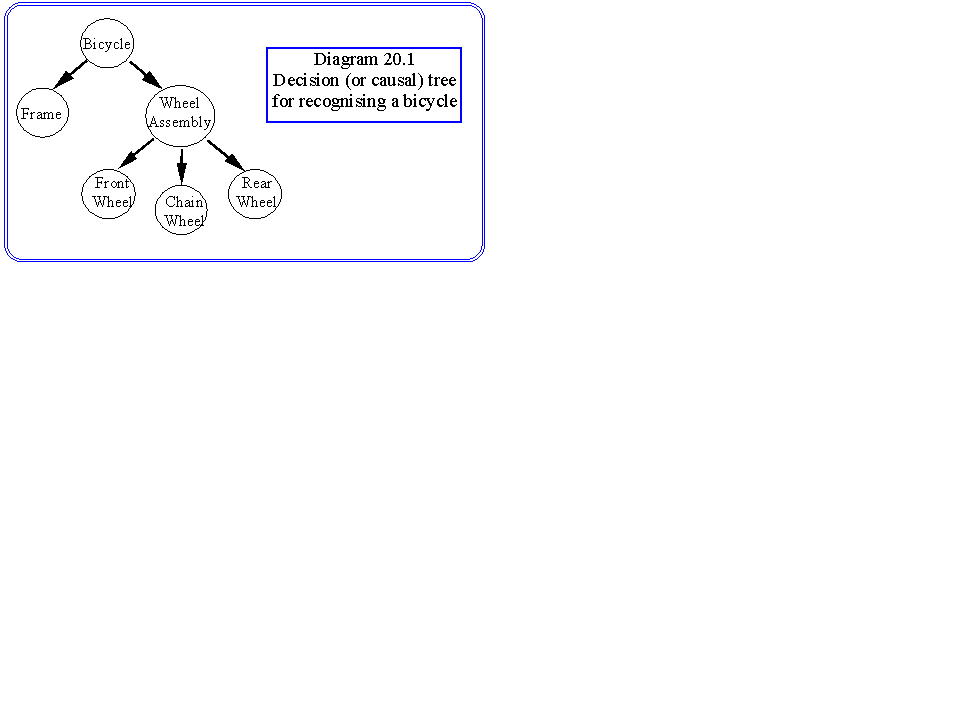
A Bayesian Network expresses a causal structure through which different information (prior and likelihood) can be combined to make an inference. For example, our prior knowledge for bicycle recognition might be expressed by rules of the kind: " a bicycle is identified by a frame two large wheels and a small wheel between them". The causal tree is shown in Diagram 20.1.
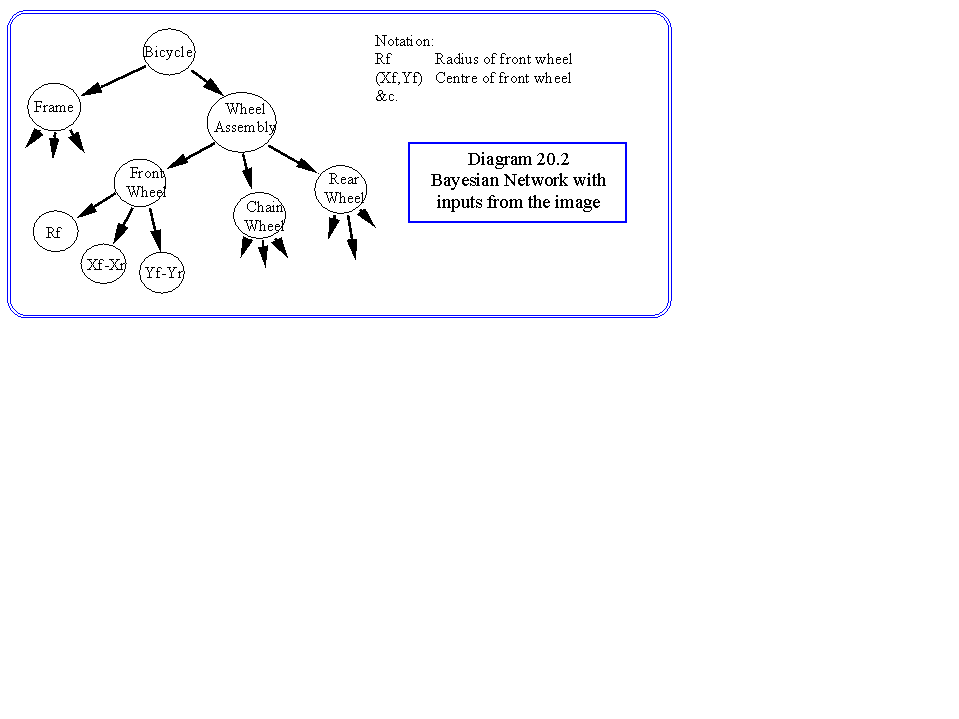
We can expand the tree at each leaf node with measurable properties of the image as shown in Diagram 20.2. The problem is to estimate the probabilities of the non leaf nodes: ie given a certain radius and centre difference of two circles what is the probability of having found a front wheel &c.
Bayes Theorem again
In the usual case where we make an inference from many pieces of information we write:
|
P(D|S1&S2& . . Sn) = |
P(S1&S2& . . Sn|D) * P(D) |
|
P(S1&S2& . . Sn) |
if S1 S2 and Sn are conditionally independent
P(S1&S2& . . Sn) = P(S1) * P(S2) * . . * P(Sn)
and P(S1&S2& . . Sn|D) = P(S1|D)*P(S2|D) * . . * P(Sn|D)
| so P(D|S1&S2& . . Sn) = |
P(S1|D) P(S2|D) . . P(Sn|D) * P(D) |
|
P(S1)P(S2) . . P(Sn) |
Consider in our example just the recognition of a front wheel:
| P(FrontWheel (FW) |Radius & XDiff & YDiff) = |
P(Radius|FW)*P(Xdiff|FW)*P(Ydiff|FW)*P(FW) |
|
(P(Radius) * P(Xdiff)*P(Ydiff)) |
P(FW), P(Radius), P(Xdiff) and P(Ydiff) are all measurable from the set of images that we process, and, as before, can be considered constants for the population (given a set of measurements). So in effect we have:
P(FrontWheel (FW) | Radius & XDiff & YDiff)=K*P(Radius|FW)*P(Xdiff|FW)*P(Ydiff|FW)
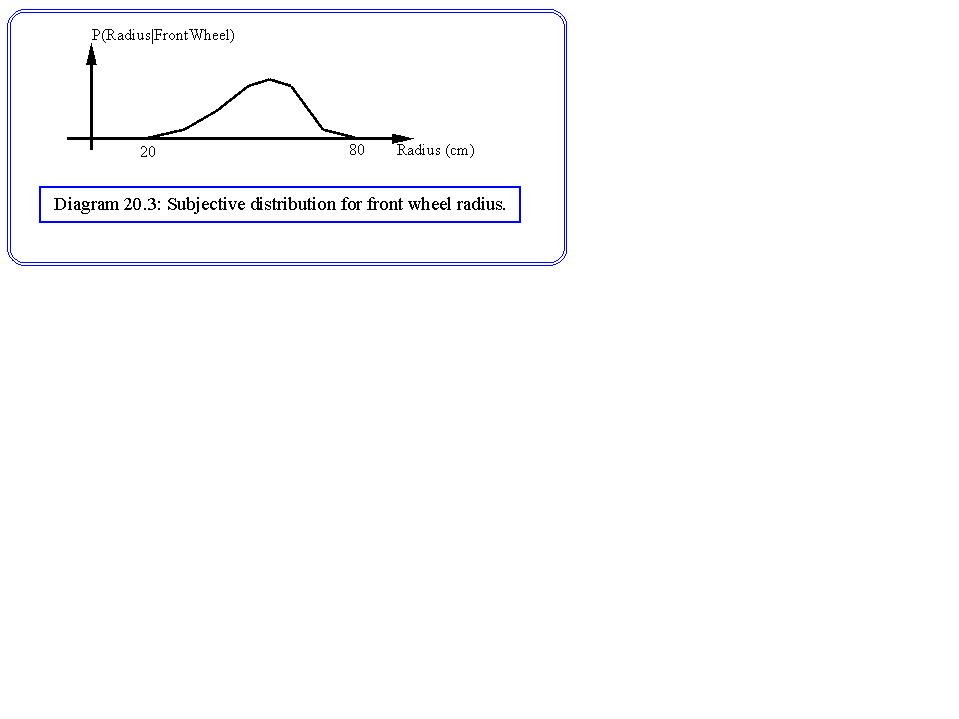
As before we can build a distribution, either subjectively or objectively, that shows the probability of finding that radius in a bicycle front wheel. The distribution might be something like diagram 20.3. If estimates are also taken of P(Radius|FW), P(Xdiff|LDR) and P(Ydiff|LDR), a probability can be found relating to whether a front wheel has been identified This can be further propagated up the decision tree.
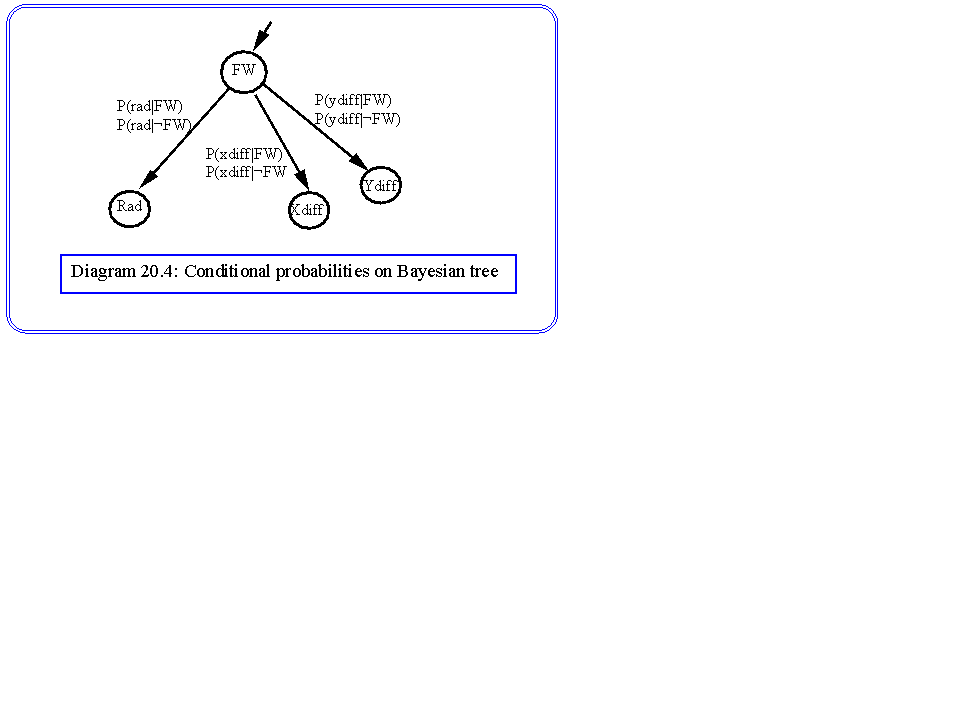
Notice that, as long as our nodes do not have multiple parents, on each arc we have a matrix of conditional probabilities, as shown in diagram 20.4. "Front wheel" has only two states ("Front wheel found" or "Front wheel not found"). If we quantise our radius measurements into say ten levels we have a ten by two matrix on the arc. Nodes may have more than two states, for example "wheel assembly" could have say three states ("wheel assembly found", "wheel assembly not found" and "possible wheel assembly found").
Instantiation
In a Bayesian Network some of the nodes (typically the leaf nodes such as radius) represent measured values. When a measurement is made they are "instantiated". We can either instatiate them directly, equivalent to supplying for example a measurement for a radius, or we can admit an uncertainty in our likelihood information by supplying a probability distribution over a set of radii.
Probability Propagation
For a given instantiation of of the measured variables (evidence) we need to compute the probability of each possible value of one or more of the other nodes. The probabilities then allow us to choose between competing hypotheses (eg bicycle or motorbike).
Evidence
Consider first the usual case of a tree where the leaf nodes are instantiated and the root node represents the hypothesis we are testing.Using Bayes theorem with assumed conditional independence we saw that there was a simple multiplicative rule for propagating the evidence:
P(FrontWheel (FW) |Radius & XDiff & YDiff) = K*P(Radius|FW)*P(Xdiff|FW)*P(Ydiff|FW)
we call the term:
P(Radius|FW)*P(Xdiff|FW)*P(Ydiff|FW)
the evidence for a node taking a particular value in general:
|
l(Bi) = |
P |
P(Dj | Bi) |
|
(sons) |
The evidence can be considered an unnormalised probability value for that node.
Conditioning
In general, if the sons are not leaf nodes then we have to condition the node, that is sum the total evidence at that node:
|
l(Bi) = |
P |
S |
l(Dj)P(Dj | Bi) |
|
(sons) |
j |
and we can consider instantiated nodes as those that have l(Ni)=1 for one value and zero for all others.
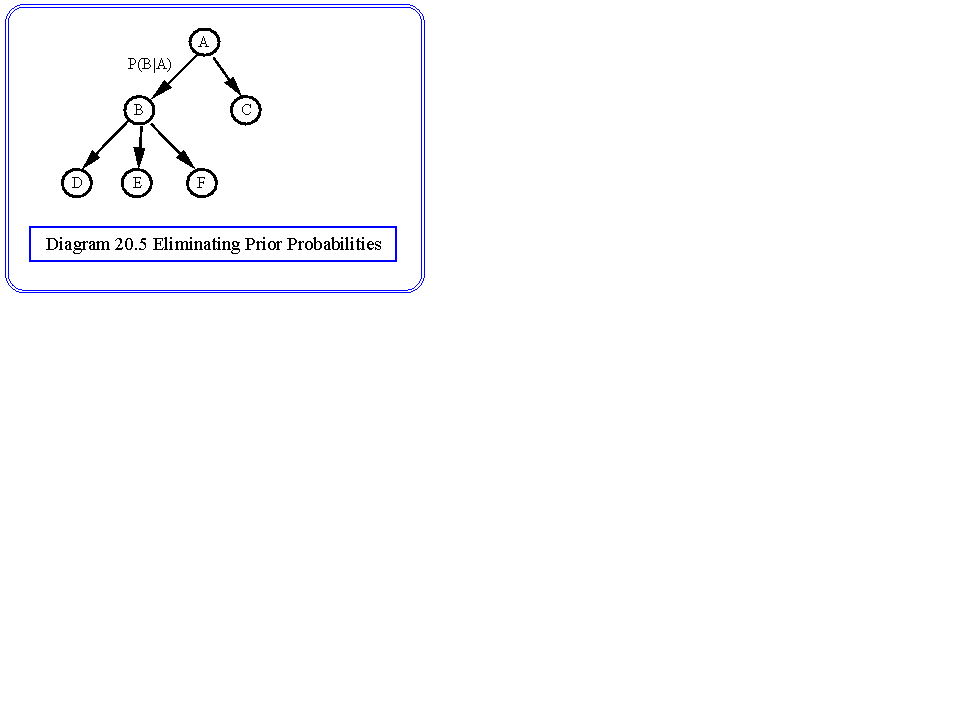
The elimination of prior probabilities
Consider the tree shown in diagram 20.5.
|
P(A|B&C) = |
P(A) P(B|A) P(C|A) |
|
(P(B) P(C)) |
|
P(B|D&E&F) = |
P(B) P(D|B) P(E|B) P(F|B) |
|
(P(D) P(E) P(F)) |
we can eliminate P(B) to get
|
P(A|B&C) = |
P(A) P(B|A) P(C|A) P(D|B) P(E|B) P(F|B) |
|
(P(C) P(D) P(E) P(F) P(B|D&E&F)) |
since the bottom is independent of A we write a = 1/(P(C) P(D) P(E) P(F) P(B|D&E&F))
P(A|B&C) = a P(A) P(B|A) P(C|A) P(D|B) P(E|B) P(F|B)
so all we need to know is the prior probabilities of the values of A, P(A), and a can be eliminated since P(A|B&C) must sum to 1 over the possible values of A.
Generalisation of Bayesian Networks
In general any node in a tree can be instantiated. If a non leaf node is instantiated a mechanism must be introduced to propagate evidence down the tree as well as up it. Instantiating a node with children is somewhat similar to determining a prior probability for the children, and this is expressed as a p value (unnormalised prior probability), similar to the l evidence that was used to express the unormalised likelihood being communicated by the children to the parent. Note also that it is not even necessary to restrict Bayesian Networks to be trees. The simplest extension is to allow multiple parents, in which exact calculations of the posterior probabilities can always be made. If loops are introduced in the causal structure (like the balance of nature: foxes rabbits and long grass) different techniques are required to avoid infinite recursion in propagating probabilities. (See Pearl, J. [1988], Probabilistic Reasoning in Intelligent Systems, Morgan-Kaufmann, San Mateo, Calif., USA.)
Conditional Independence
An important assumption in propagation of probabilities is that the children nodes are conditionally independent. It may be necessary to check this assumption. Considering the estimate of FrontWheel we have used:
P(Radius|FW) P(Xdiff|FW) P(Ydiff|FW )
but maybe in the population, these are not independent, ie we could write say:
Xdiff = f (Radius)
if such a relationship exists then Bayes theorem has not been applied correctly. The relationship can be found by correlating the input data, and if the correlation coefficient is high, we know that the structure is incorrect, and we must correct it for example by:
Incorporating the known functional relationship
Removal of correlated variables
Altering the network structure
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}