In this question, assume a static-pipeline machine with the following
characteristics:
- Integer arithmetic always takes just one clock cycle.
- Delayed conditional branch.
No stalls are caused the branch.
- FP operations are identified at the ID stage and are dispatched
to separate non-pipelined functional units. Results are routed
direct to the WB stage where they are handled in issue order.
- There are two FP functional units, one for add/subtract, the
other for multiply/divide.
- FP load takes 3 cycles,
FP addition takes 4 cycles.
- There is full bypassing, i.e. wherever a hazard can be resolved using
bypassing, the bypass circuitry is present.
- Since FP registers are separate from integer registers, updates
(write-back) to FP registers can occur in the same cycle as updates to
integer registers.
Consider the following loop:
LOOP: SD 0(R1),F4 ; stores into M[i]
ADDD F4,F0,F2 ; adds to M[i+1]
LD F0,16(R1) ; loads M[i+2]
BLT R1,R2,LOOP ; delayed branch if R1 < R2
ADD R1,R1,#8 ; executed whether branch taken or not
Assume that R1 initially points to the start of an array M of doubles,
and R2 points to the end.
- Using your paper sideways, draw a diagram showing the timing for the
execution of the loop. You will need to look at more than one
iteration.
- Indicate clearly where forwarding occurs
- No stalls should be necessary
- What is the average CPI when the loop is executed many times?
- Explain what this loop does, and describe how it is likely to be used
to perform a straightforward useful function. Show any initialisation needed. What
is going on? How does the performance of this loop compare with a
straightforward implementation?
The loop in Exercise 6.1 is the core of a fast implementation of a
simple operation. Write down the assembler code for the
straightforward version of the loop. Consider how it would be
executed on a dynamically-scheduled version of the machine using
Tomasulo's algorithm with a re-order buffer, and compare its timing
with the behaviour of the loop shown in Exercise 6.1. What do you
conclude?
Paul Kelly, Imperial College, 2004
In this question, assume a static-pipeline machine with the following
characteristics:
- Integer arithmetic always takes just one clock cycle.
- Delayed conditional branch.
No stalls are caused the branch.
- FP operations are identified at the ID stage and are dispatched
to separate non-pipelined functional units. Results are routed
direct to te WB stage where they are handled in issue order.
- There are two FP functional units, one for add/subtract, the
other for multiply/divide.
- FP load takes 3 cycles,
FP addition takes 4 cycles
- There is full bypassing, i.e. wherever a hazard can be resolved using
bypassing, the bypass circuitry is present.
- Since FP registers are separate from integer registers, updates
(write-back) to FP registers can occur in the same cycle as updates to
integer registers.
Consider the following loop:
LOOP: SD 0(R1),F4 ; stores into M[i]
ADDD F4,F0,F2 ; adds to M[i+1]
LD F0,16(R1) ; loads M[i+2]
BLT R1,R2,LOOP ; delayed branch if R1 < R2
ADD R1,R1,#8 ; executed whether branch taken or not
Assume that R1 initially points to the start of an array M of doubles,
and R2 points to the end.
- Using your paper sideways, draw a diagram showing the timing for the
execution of the loop. You will need to look at more than one
iteration.
Take care to identify and explain all possible hazards.
SD 0(R1),F4 IF ID EX M
ADDD F4,F0,F2 IF ID EX EX EX EX WB
LD F0,16(R1) IF ID EX M M M WB
BLT R1,R2,LOOP IF ID EX
ADD R1,R1,#8 IF ID EX M WB
SD 0(R1),F4 IF ID EX M
ADDD F4,F0,F2 IF ID EX EX EX EX WB
LD F0,16(R1) IF ID EX M M M WB
BLT R1,R2,LOOP IF ID EX
ADD R1,R1,#8 IF ID EX M WB
Basic idea: (1 marks)
No stalls occur. (1 marks)
Hazards:
- There are no data (RAW) hazards: each instruction uses a register
generated by the next instruction in the loop, giving the maximum
possible time (unless we unroll and use different registers)
for the instruction to complete.
- There are no WAR hazards because, in a static pipeline like this
one, instructions are always issued (and therefore pick up their
operands) in order.
- There are no WAW hazards because, although we need concurrent WBs
(which the hardware must accommodate), the registers in question
are different.
- You were asked to assume no control hazards. This could be
achieved by relying on branch prediction to assume the branch will
be taken. In this machine, the branch will be resolved by the
EX or perhaps ID stage, which is easily early enough to avoid
the registers being updated with the results of wrongly-executed
instructions.
Sensible comments about hazards: (2 marks)
- What is the CPI when the loop is executed many times?
Since there are no stalls, the CPI tends to 1 when the number of iterations is large.
(1 marks)
- Explain what this loop does, and describe how it is likely to be used
to perform a useful function. Show any initialisation needed. What
is going on? How does the performance of this loop compare with a
straightforward implementation?
The loop really does this:
for i = 0 to N do
A[N] := A[N] + K
(2 marks)
The code is designed to allow as much time as possible for load and FP
add operations to take place, without unrolling. To do this,
instructions are migrated backwards to the earliest point they can be
issued. An instruction can be migrated round the loop, so it
initiates work belonging to a later iteration.
When this happens, it is also necessary to migrate the instruction
into the start-up sequence, so that the first two iterations are
primed appropriately:
LD F0,(R1) ; loads M[N]
ADDD F4,F0,F2 ; compute new M[N] ready for SD
LD F0,8(R1) ; loads M[N+1] ready for ADDD
Loop: SD 0(R1),F4 ; stores into M[i]
ADDD F4,F0,F2 ; adds to M[i+1]
LD F0,16(R1) ; loads M[i+2]
BLT R1,R2,LOOP
ADD R1,R1,#8
(2 marks)
You might also want to handle the last two iterations separately to avoid
loading elements beyond the end of M).
A straightforward implementation of the loop above would look like:
Loop: LD F0,0(R1)
ADDD F4,F0,F2 ; adds to M[i]
SD 0(R1),F4 ; stores into M[i]
BLT R1,R2,LOOP
ADD R1,R1,#8
This implementation suffers stalls in a static pipeline:
cycle 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
LD F0,0(R1) IF ID EX M M M WB
ADDD F4,F0,F2 IF ID EX EX EX EX WB (stall due to F0)
SD 0(R1),F4 IF ID EX M WB (forwarding of F4 to M stage)
BLT R1,R2,LOOP IF ID EX M WB
ADD R1,R1,#8 IF ID EX M WB
LD F0,0(R1) IF ID EX M M M WB
...
Exactly how many stalls depends on the design of the floating
point units. In a static-schedule design the constraint that ID stages
access registers in-order leads to very poor performance.
The simple loop gets a CPI of 10/5=2.0. With a 10GHz clock, the
clever loop would take 100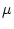 s to do 1M iterations, the simple one 200s.
The simple one is 100% slower, the clever one takes
100/200=50% as long, so it's 50% faster.
s to do 1M iterations, the simple one 200s.
The simple one is 100% slower, the clever one takes
100/200=50% as long, so it's 50% faster.
Total for 6.1: (8 marks)
(This exercise is based on an example in Hennessy and Patterson
(first ed), page 325).
The loop in Exercise 6.1 is the core of a fast implementation of a
simple operation. Write down the assembler code for the
straightforward version of the loop. Consider how it would be
executed on a dynamically-scheduled version of the machine using
Tomasulo's algorithm, and compare its timing with the behaviour of the
loop shown in Exercise 6.1. What do you conclude?
Loop: LD F0,0(R1)
ADDD F4,F0,F2 ; adds to M[i]
SD 0(R1),F4 ; stores into M[i]
ADD R1,R1,#8
BLT R1,R2,LOOP
(1 marks)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
LD F0,0(R1) IF IS RO M M M WB
ADDD F4,F0,F2 IF IS RO EX EX EX EX WB (F0 fwded from LD via CDB)
SD 0(R1),F4 IF IS RO M (F4 fwded from ADDD via CDB)
ADD R1,R1,#8 IF IS RO EX WB
BLT R1,R2,LOOP IF IS RO EX WB
LD F0,0(R1) IF IS RO M M M WB (loop-carried structural hazard due to CDB)
ADDD F4,F0,F2 IF IS RO EX EX EX EX WB
SD 0(R1),F4 IF IS RO M
ADD R1,R1,#8 IF IS RO EX WB
BLT R1,R2,LOOP IF IS RO EX WB
LD F0,0(R1) IF IS RO M M M WB
ADDD F4,F0,F2 IF IS RO EX EX EX EX WB
SD 0(R1),F4 IF IS RO M
ADD R1,R1,#8 IF IS RO EX WB
BLT R1,R2,LOOP IF IS RO EX WB
(3 marks)
(As in the previous question, various variations on this answer are acceptable).
Conclude: you can sometimes, maybe often, get the performance advantage of
dynamic scheduling via compile-time instruction scheduling.(2 marks)
Note the need for RO to initiate two operations in one cycle.
There is contention for the CDB, which delays forwarding the some iterations (eg iteration 2, cycles 12-13).
However, delay does not accumulate since at most one instruction is issued
per cycle, and the CDB handles one result per cycle.
Total for 5.3: (6 marks)
Total: 20 marks
Paul Kelly, Imperial College, 2004


