The latency models for store-and-forward routing and cut-through routing can be used to estimate and compare the cost of communication operations.
For this problem assume:
A one-to-all broadcast can be implemented by:
for i = 1 to 7
processor 0 sends its partition of the array to processor i
end for
A right shift by 4 places can be implemented by:
for all i < 4
processor i sends its partition of the array to processor i+4
(You may assume that the bandwidth of all the channels is that of the most heavily loaded channel.)
For the calculation of one-to-all broadcast it was assumed that the send was blocked, ie the send did not return control to the process until the packet had been received.
How might the sending processor detect that the packet has been received? What are the implications of this to the cost of a blocking send?
What is the time taken to complete the one-to-all broadcast for non-blocking sends under the two schemes?
For a number of aggregate communication patterns, such as right shift, the latency difference between using store-and-forward and worm-hole routing are not significant.
Why then have most current MPP designers chosen to use worm-hole routing?
Paul Kelly and Hing Wing To, Imperial College, December 1999
for i = 1 to 7
processor 0 sends its partition of the array to processor i
end for
Recall that the latency for store-and-forward is:
and that the simple model of latency for cut-through (worm-hole)
routing is:
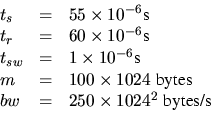
Under store-and-forward routing:
![\begin{displaymath}T_{sf} = \begin{array}[t]{l}
t_s + 1(t_{sw} + \frac{m}{bw}) ...
... \vdots \\
t_s + 7(t_{sw} + \frac{m}{bw}) + t_r
\end{array}\end{displaymath}](img8.gif)
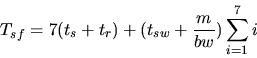
![\begin{displaymath}T_{sf}
\begin{array}[t]{cl}
= & 7 (55 \times 10^{-6} + 60 \t...
... 3.90625 \times 10^{-4})
28\\
= & 0.01177 \mbox{s}
\end{array}\end{displaymath}](img10.gif)
Under cut-through routing:
![\begin{displaymath}T_{ct} = \begin{array}[t]{l}
t_s + 1t_{sw} + \frac{m}{bw} + ...
...
\vdots \\
t_s + 7t_{sw} + \frac{m}{bw} + t_r
\end{array}\end{displaymath}](img12.gif)
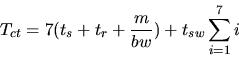
![\begin{displaymath}T_{ct}
\begin{array}[t]{cl}
= & 7 (55 \times 10^{-6} + 60 \t...
...^{-4}) + 28 \times 10^{-6}\\
= & 0.002762 \mbox{s}
\end{array}\end{displaymath}](img14.gif)
The cut-through routing version performs better than the store-and-forward routing version. Long packets are sent therefore the latency of the individual sends in the cut-through routing scheme are relatively independent of the distance the packets are sent. In contrast the latency of the distant sends is considerably higher in the store-and-forward version.
for all i < 4
processor i sends its partition of the array to processor i+4
(You may assume that the bandwidth of all the channels is that of the most heavily loaded channel.)
The communication pattern for right shift by four places is:
All four sends occur simultaneously, therefore the total latency is that of the longest send. In this case all the sends have the same cost.
Under store-and-forward routing there is no contention assuming all the sends begin at the same time, since the packets are being stored one switch ahead of each other.
Therefore the time for one send is:
![\begin{displaymath}T_{sf}
\begin{array}[t]{cl}
= & 55 \times 10^{-6} +
4 (1 \...
...2}) +
60 \times 10^{-6} \\
= & 0.0016815 \mbox{s}
\end{array}\end{displaymath}](img16.gif)
Assume worm-hole routing with at least four virtual channels. The bandwidth of the channel between P3 and P4 will have four packets traversing it by time-division multiplexing. Therefore the bandwidth of the channel is only a fourth of the raw channel bandwidth.
Assume that this is a bottleneck and that the bandwidth of all channels is therefore the same as the most heavily loaded channel.
Therefore the time for one send is:
![\begin{displaymath}T_{ct}
\begin{array}[t]{cl}
= & t_s + 4 t_{sw} + \frac{4m}{b...
..._s + 4 (t_{sw} + \frac{m}{bw}) + t_r \\
= & T_{sf}
\end{array}\end{displaymath}](img18.gif)
The performance under both routing schemes is the same. The advantage of the cut-through routing scheme when sending messages over long distances is offset by the loss in available bandwidth caused by sharing the channel between multiple messages.
Paul Kelly and Hing Wing To, Imperial College, December 1999