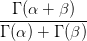 xα−1(1 − x)β−1
xα−1(1 − x)β−1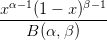
Beta distribution is a type of statistical distribution, which has two free parameters. It is used as a prior distribution in Bayesian inference, due to the fact that it is the conjugate prior distribution for the binomial distribution, which means that the posterior distribution and the prior distribution are in the same family.
The probability distribution function (pdf) of the beta distribution is defined as,
| f(x; α,β) = | xα−1(1 − x)β−1 | ||
| = | | (1) |
Considering the classical Bernoulli problem (repeated coin flipping), after n trials, there are s successes (heads) and f failures (tails). Let a random variable x denote the success probability of each trial. The likelihood for parameters s and f given x = p is is the following binomial distribution,
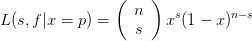 | (2) |
If belief about prior probability information is reasonably well approximated by a beta distribution,
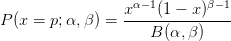 | (3) |
According to Bayes’s theorem, the posterior probability is given by the product of the likelihood function and the prior probability normalised by the integral as follows,
| P(x = p|s,f) = | 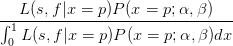 | ||
| = | 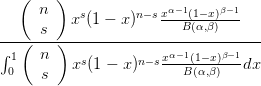 | ||
| = | 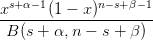 | (4) |
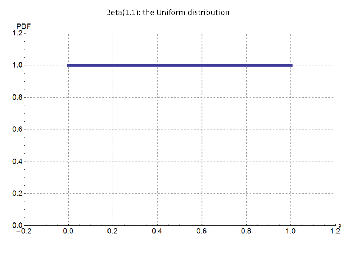
For the Bayes’s prior probability (Beta(1,1), Figure 1), the posterior probability is,
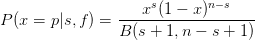 |
with mean = 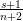 and mode =
and mode =  .
.
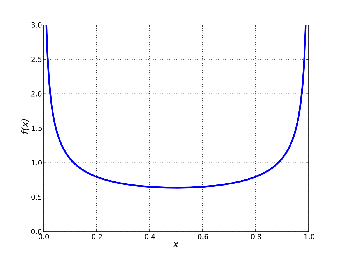
For the Jeffrey’s prior probability (Beta(1/2,1/2), Figure 2), the posterior probability is,
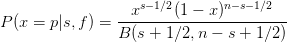 |
with mean = 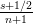 and mode =
and mode = 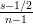 .
.
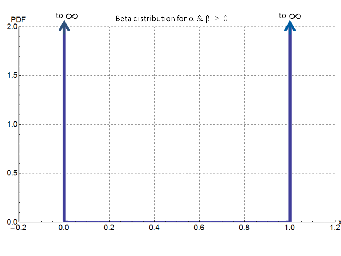
For the Haldane’s prior probability (Beta(0,0), Figure 3), the posterior probability is,
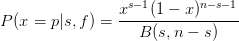 |
with mean =  and mode =
and mode = 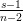 .
.
The Dirichlet distribution is a family of continuous multivariate probability distributions parameterised by a vector α of positive reals. It is the multivariate generalisation of the beta distribution. It is often used as the prior distribution in Bayesian inference and it is the conjugate prior of the categorical distribution and multinomial distribution.
The pdf of the Dirichlet distribution is defined as,
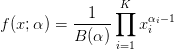 | (5) |
where α = (α1,α2, ,αK) denotes the concentration parameters (αi > 0),
K ≥ 2 denotes the number of categories, B(α) =
,αK) denotes the concentration parameters (αi > 0),
K ≥ 2 denotes the number of categories, B(α) = 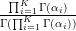 , and the
support x = (x1,x2,
, and the
support x = (x1,x2, ,xK) follows xi ∈ [0, 1] and ∑
ixi = 1. The support
is in fact a simplex.
,xK) follows xi ∈ [0, 1] and ∑
ixi = 1. The support
is in fact a simplex.