Lecture 1: Introduction to Vision Systems
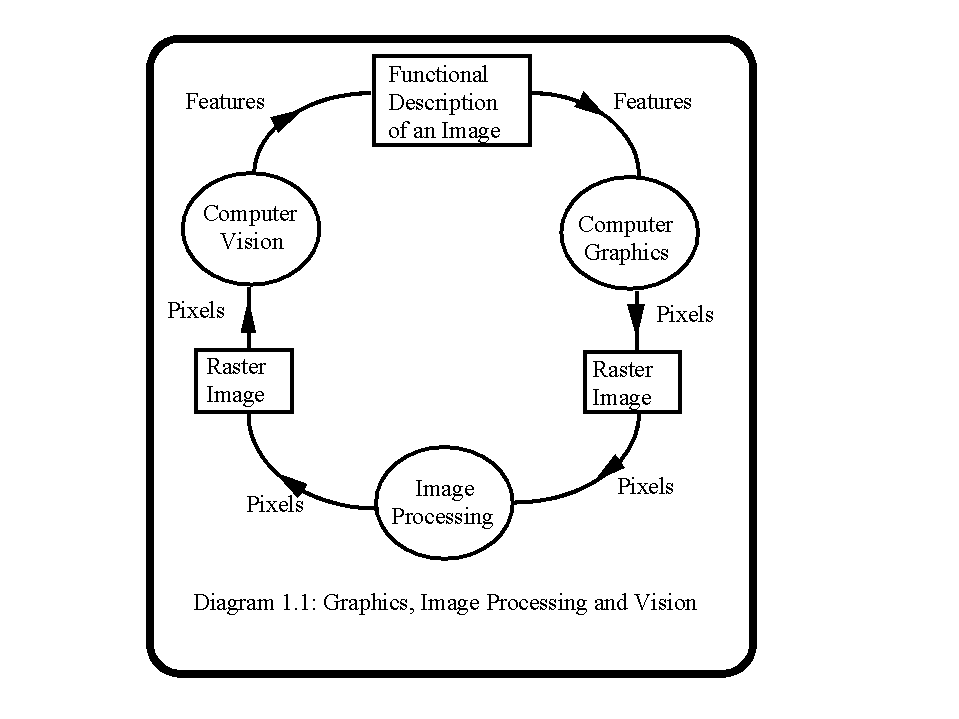
Graphics, Image Processing and Vision
The field of vision is closely related to image processing and frequently the name image processing is used to cover both fields. The meaning adopted in this course is illustrated by diagram 1.1. Image processing is concerned with improving the quality of an image. The typical tasks undertaken in image processing are:
In all these cases we are taking an image, and processing it to improve its visual appearance, or to make features more apparent to the viewer.
By contrast, in vision, we take images and extract features. The end point may be a different kind of image, or may be some more abstract feature description. The types of tasks we are concerned with are:
Vision is the exact opposite process to graphics. In graphics, we start with a functional description and end up with a picture representation which is a set of pixels. In the case of graphics, we have complete information and so the problems are largely algorithmic. For vision, we do not have complete information, and therefore we must use domain specific knowledge, assumptions or heuristics to achieve our goal.
Application oriented vision systems
Application oriented systems have been quite successful over the last few years. Typical applications are:
Vision based robots
Quality assessment systems
The construction of these systems is highly domain dependent, but none the less some techniques have been devised which have usefulness beyond their immediate application. Also included here are the so called high performance vision systems which use artificial intelligence methods. Here the identification of image features depends on heuristics which inevitably create application specificity.
General purpose vision systems
The intention is to provide a system that can recognise image properties in a wide variety of image types. So far the only successful systems are pattern recognisers which can be trained. However, general purpose vision remains an important research goal. A common approach in constructing general purpose vision systems is to use brain modelling. That is to say we attempt to construct a system which works in a way analogous to the human vision system. Such systems fall into two classes:
- low level in which we model the micro structure of the brain as far as it is understood. Models of the visual cortex (and other brain structures) have been provided by physiologists (Hubel and Wiesel) and have formed the basis of neural net systems such as Wisard.
In practice, even the most general purpose systems will have application specificity.
Computational Models for vision
In designing a vision system some specific questions need to be answered:
1. What information is sought from the image.
2. How is it manifest in the image
3. What a-priori knowledge is required to recover the information
4. What is the nature of the computational process
5. How should the required information be represented
The implications of theses questions are as follows.
Intrinsic Characteristics
Considering question 1 and 2 in the above list we need to establish a relationship between physical entities and intrinsic characteristics. If, for example we wish to distinguish and extract the position of a house in a scene containing trees, we can use the fact that straight lines are an intrinsic characteristic of a house, but not of trees. Hence we would choose to extract straight lines from the raw images. Conversely, if we wish to separate sea from land from an aerial photograph, we could choose the intrinsic characteristic that water is of uniform appearance, and apply a region based segmentation algorithm tuned to extract large uniform regions. Intrinsic characteristics must be matched to established techniques.
Prior Knowledge
Question 3 is the most important since as noted above the goal of vision is to provide information which is not in the picture. Some prior knowledge will always be necessary. It is universally accepted that human vision depends on a vast amount of knowledge. To establish a relationship between pixel brightness and image properties, we will need to have some form of scene model, illumination model and sensor model. The scene model may include such information as the type of features we are trying to detect, or in more general cases make assumptions about properties such as smoothness or convexity. The illumination model will contain information about the position and characteristics of the light source and the surfaces reflectance properties. The sensor model will describe the position and optical performance of the cameras used, and the noise and distortion applied by the digitisation and storage media.
Resource limitations
Question 4 will include a consideration of computational resources, and the time required to process the image. The exact nature of the computational process will be established by the answers to questions 1 2 and 3, however, realtime requirements need to be taken into account here. For example if we wish to assess the condition of a motorway surface while driving over it at 60mph, each sampled image must be processed in a fixed time, which in turn places a requirement on the hardware.
Knowledge representation
Representation is important for vision partly for the encoding of knowledge in a useful form, but also in the presentation of results in an understandable form. Typically, humans find it difficult to describe exactly the visual properties on which they make decisions.
Levels of Vision
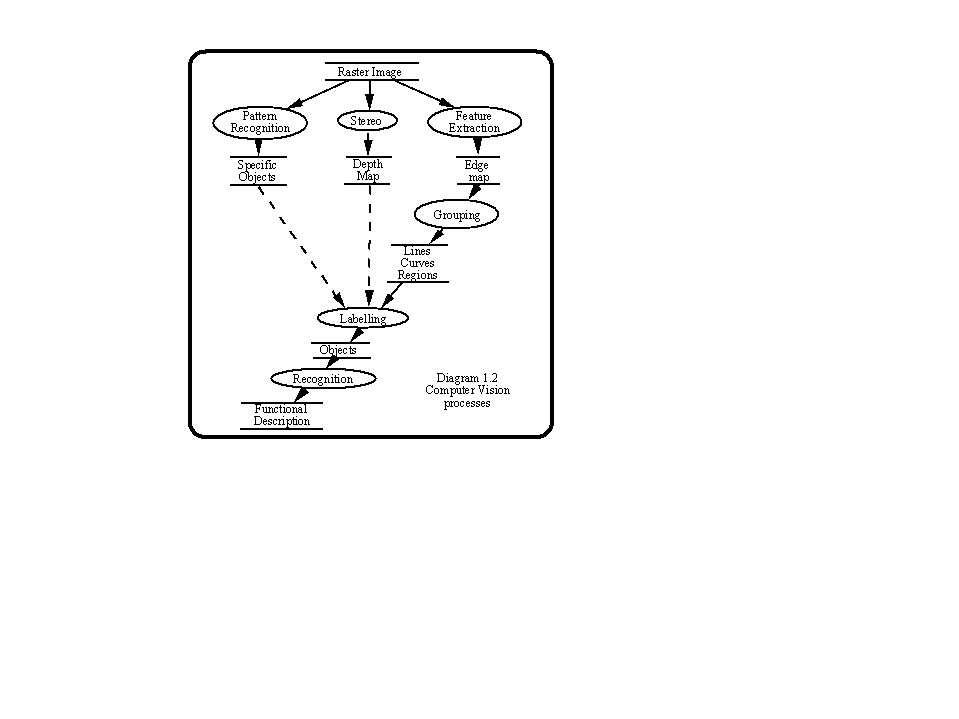
It is now generally accepted that vision may be treated in three different levels of processing: low, intermediate and high. The boundaries between these are blurred, but loosely are as follows:
Low level processing:
Operations carried out on the pixels in the image to extract properties such as the gradient (with respect to intensity) or depth (from the viewpoint) at each point in the image. We may for example be interested in extracting uniform regions, where the gradient of the pixels remains constant, or first order changes in gradient, which would correspond to straight lines, or second order changes which could be used to extract surface properties such as peaks, pits ridges etc. Low level processing is invariably data driven, sometimes called bottom up. It is the area where modelling the visual cortex functioning is most appropriate.
Intermediate level processing:
The intermediate level of processing is fundamentally concerned with grouping entities together. The simplest case is when we group pixels into lines. We can then express the line in a functional form. Similarly, if the output of the low level processing is a depth map, we may further need to distinguish object boundaries, or other characteristics. Even in the simple case where we are trying to extract a single sphere, it is no easy process to go from a surface depth representation to a centre and radius representation. Since intermediate level processing is concerned with grouping, much of the recent work has concentrated on using perceptual grouping methods.
High Level Processing
Interpretation of a scene goes beyond the tasks of line extraction and grouping. It further requires decisions to be made about types of boundaries, such as which are occluding, and what information is hidden from the user. Further grouping is essential at this stage since we may still need to be able to decide which lines group together to form an object. To do this, we need to further distinguish lines which are part of the objects structure, from those which are part of a surface texture, or caused by shadows. High level systems are therefore object oriented, and sometimes called top down. They almost always require some form of knowledge about the objects of the scene to be included. Diagram 1.2 illustrates the three levels at which vision is usually treated, and places in context some of the techniques that we shall be discussing.
Principal of Least Commitment
If we adopt the three level approach, then it is clear to see that as we move from one level to the next higher we are throwing away some of the information. For example, if we extract the points on an image that we expect to form edges, by differentiation the image and setting a threshold, we eliminate a substantial number of pixels. This is desirable from the computational viewpoint, since we wish to minimise the calculations carried out on edge points, however, we run the risk removing weak but significant edge points from our image, and so making a wrong decision at a later stage. Similarly, when we extract line segments, we will reject certain segments on the basis the edge point data, and depending on the thresholds we choose, we again may reject an edge which belongs to an object. The principal of least commitment states that we should avoid these possibilities by carrying as much information from one level to the next. The limit to which it is feasible to do this will depend on the computational resources open to us.
{kind=link}
{kind=link}