Lecture 10: Object Recognition in two dimensions
Many of the techniques for vision that we have described above can be used in manufacturing for a variety of processes such as sorting objects, orienting objects or determining exact positions for robot arm movements. One dimensional systems are now commonplace and include bar code readers and counting machines. Two dimensional systems, using simply bi-level images can be used for a wide variety of tasks, and systems using grey level images are beginning to find application. High resolution is not required for manufacturing vision systems. This is because the optical system of a standard camera, though acceptable for visual perception, will introduce a distortion at least 1%. Hence, a resolution of greater than 256x256 is not going to add significantly to the ability at recognition. Moreover, the low resolution is advantageous in reducing the computing time of some of the algorithms that we will discuss.
Template Matching
The simplest solution to object recognition is to find the best match of the object with a number of characteristic templates. However, to do this exhaustively, we need to check all possibilities.
A Mathematical Interlude, which may look familiar to those with good memories:
Correlation defines a way of combining two functions. In the most general form it is defined as a continuous integral which in two dimension is:
|
¥ |
¥ |
||
|
C(x,y) = |
ò |
ò |
I(p,q) f(p+x,q+y) dp dq |
|
-¥ |
-¥ |
The function f in the above equations is usually called a template. For our purposes we are interested in discrete functions of finite size. For these, the correlation integral simplifies to:
|
xres |
yres |
||
|
C(x,y) = |
S |
S |
I(p,q) * f(p+x,q+y) |
|
p=1 |
q=1 |
where I(x,y) is the discrete function defining the pixel values, f(u,v) is the template function, and [1..xres,1..yres] is the range over which I(x,y) is non zero, i.e. the resolution of the picture. The normal restriction on the above equations is that the functions are symmetric about zero, ie
|
¥ |
¥ |
¥ |
¥ |
|||
|
ò |
ò |
I(p,q) dp dq = 0 |
and |
ò |
ò |
f(p,q) dp dq = 0 |
|
-¥ |
-¥ |
-¥ |
-¥ |
For any image, this may be arranged by subtracting the average value from each image point.
In the simplest case, we need to determine the best fit of the template to the image. This is the point where C(x,y) is a maximum, and the [x,y] determines the position in the image where the template is recognised.
Discriminants
Although template matching can provide a solution for cases where the object is aligned with the axes, to check all possible positions and orientations of the templates for the best match is clearly very time consuming. Hence, one approach to define a set of discriminants which will separate out the different objects that we wish to identify or to sort.Discriminants are any simple object property that can be computed from the image, but they must have one important property, vis that they are independent of the object position. The simpler ones depend only on the boundary of the objects, but more complex ones can involve the grey levels and the shape of the boundaries.
Object area and perimeter
The simplest features that we can extract from the pixel image are object area and perimeter. Providing that the image is bi level, and that a single object is present in the image, we can of course computed the area by summing all the pixels of the camera image. This method is, however, inefficient since it requires every pixel in the image to be processed. Early systems traced round the boundary at the pixel level, but this was rather inaccurate, being prone to alias effects, particularly when trying to determine perimeters. In cases where a piece wise boundary has been determined using say a Hough transform, the area can be measured, as illustrated by diagram 10.1, by processing the edge vectors of a polygon in order, adding the area under the edge vectors when moving to the right, and subtracting it when moving to the left. In this case perimeter can be computed accurately from the coordinates of the vertices.
Moments
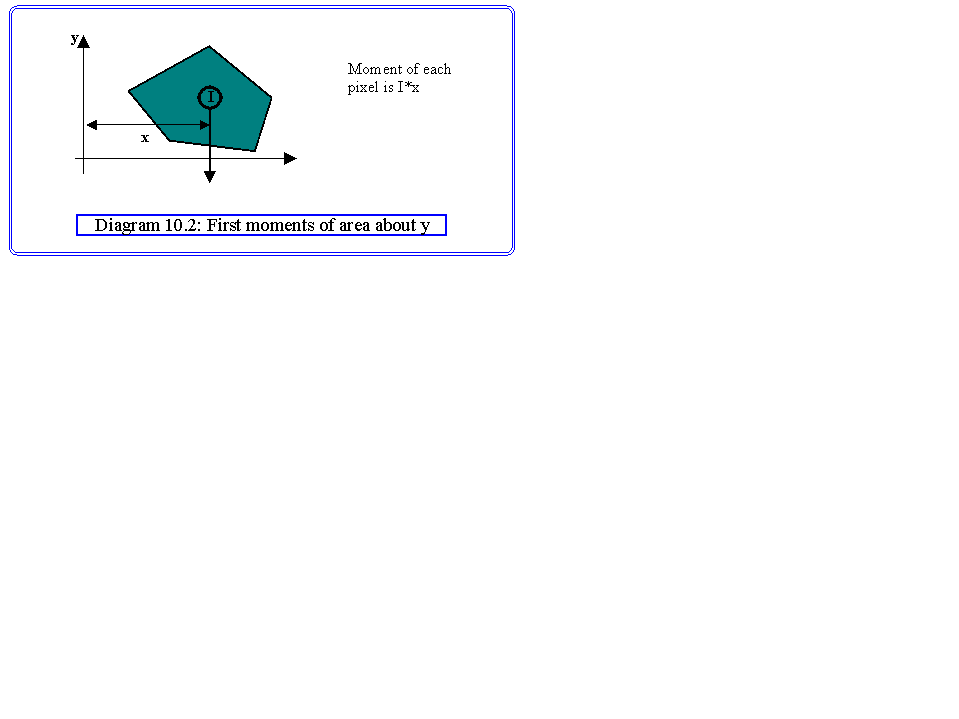
Area and perimeter may be sufficient discriminants in many cases, but for better recognition, moments of area are frequently used. Moments are defined equivalently to mechanical moments treating the grey level at a pixel to be equivalent to a weight as shown in Diagram 10.2. Formally, central moments are defined as an integral over the object, but since the image function is only defined at the pixels we can replace the integral with a sum:
|
Mpq = |
S |
(x-µx)p (y-µy)q I(x,y) |
|
Object Pixels |
Where I(x,y) as before is the image function, {µx, µy} is the centre of gravity of the image and p and q are the orders of the moments. The centre of gravity is defined as follows:
| µx = |
S |
I(x,y)*x / S I(x,y) |
|
Object pixels |
||
| µy = |
S |
I(x,y)*y / S I(x,y) |
|
Object pixels |
Note that the moments are always taken around the centre of gravity to ensure that they are independent of the position of an object in the image. Consider the second order moment. We can look at this in terms of two components, a second moment about the x direction (p=0,q=2) and a second moment about the y direction(p=2, q=0)
|
M20= |
S |
I(x,y)*(x-µx)2 / S I(x,y) | (about the y direction) |
|
Object pixels |
|||
|
M02= |
S |
I(x,y)*(y-µy)2 / S I(x,y) | (about the x direction) |
|
Object pixels |
The second moment gives us a measure of how spread out the object is. For example, the polygon in the diagram 10.3 will clearly have a much higher value of M20 than the square, even though their area and perimeter may be very close. If we consider the vector formed by the two components:
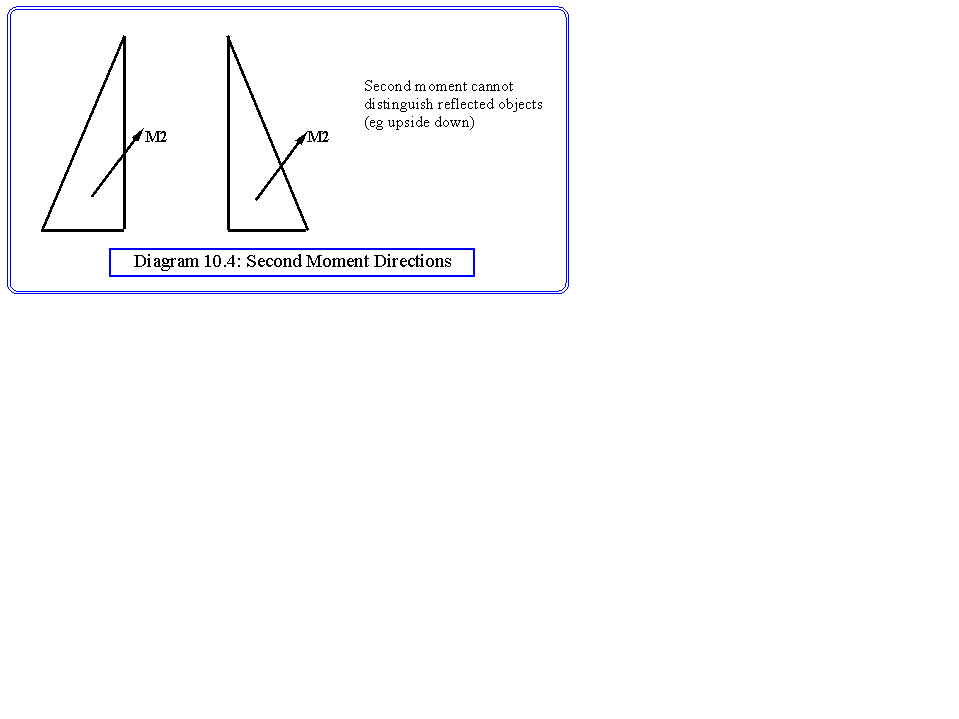
M2 = [M20,M02]
Its magnitude is position independent, and so can be used as a discriminant, and its direction can be used to measure the orientation of the object. This is a useful property for control of a robot gripper. Note though, that the second moment is always positive, and hence the second moment cannot detect reflected objects (see diagram 10.4). However the same fact means that M20+M02 may be used in place of the normal Euclidian distance for a magnitude discriminant. There are many other ways in which useful discriminants can be constructed from moments. For example, (M30-3M12)2 + (3M21-M03)2 is one that uses the third moments. Rarely however do higher order moments yield any more discriminant power than the second.
Energy and Entropy
When we considered characterising textures we looked at energy and entropy of the co-occurrence matrices as possible discriminants. These measures can equally well be applied to objects where the shade or texture may have given characteristics. The image intensities need to be normalised before the discriminants are computed to account for varying light conditions
Discriminants based on geometric features
Area, perimeter, moments energy and entropy do not rely on any particular feature of the objects being recognised, and this makes them widely applicable for sorting and orienting objects. However, if the number of objects is great they may not be sufficient to discriminate all possibilities. In these cases it becomes necessary to extract features, and these are object specific. Possible features for discrimination, for objects with polygonal outline are:
Number of vertices
Distance of each vertex from the centre of gravity
Angle subtended by the vertices at the centre of gravity
etc
{kind=link}
{kind=link}
{kind=link}
{kind=link}