The Jagged Neurosymbolic Frontier
Invariant inference, execution oracles, and the limits of pure AI audits: how a "poor man's neurosymbolic" loop forces LLMs to write down their assumptions, then fuzzes the assumptions themselves.
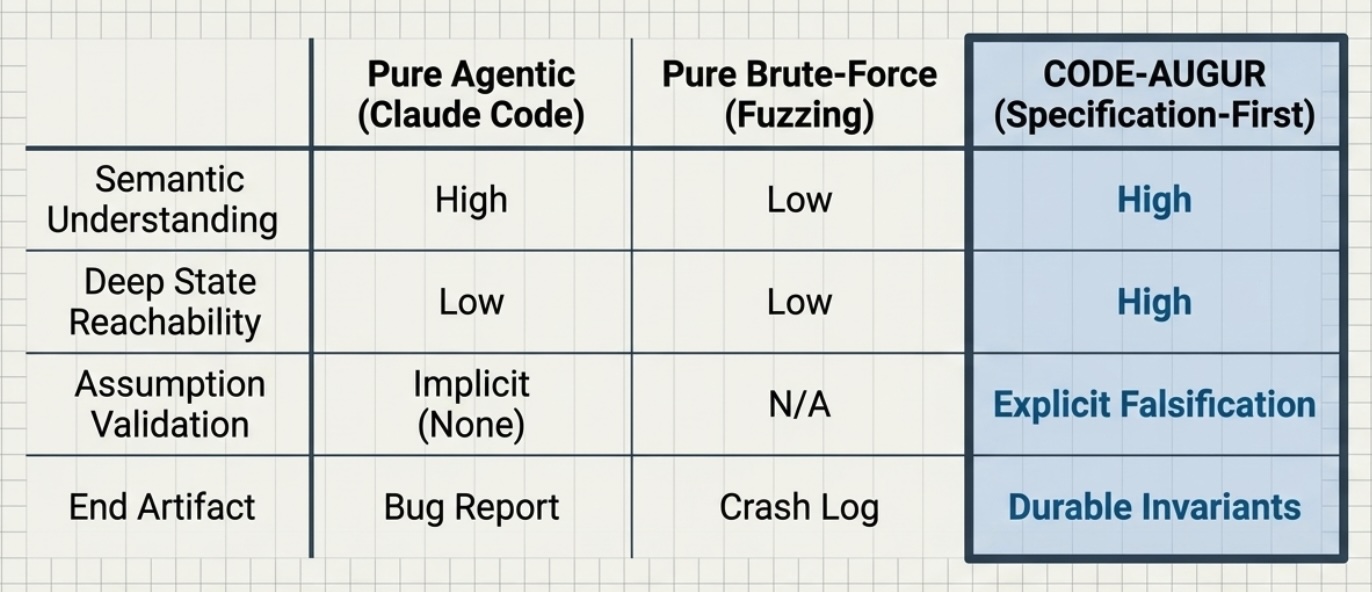
Over the coming months, the software engineering landscape will see an aggressive convergence of LLM-based intuition and precise reasoning systems. The industry is beginning to realize that pure generative models can be too unpredictable and token-hungry, while formal theorem provers remain too rigid to scale economically.
The middle ground, where fluid, probabilistic neural nets are bound by rigid, deterministic verification harnesses, is where we will see some exciting results related to software security and correctness. When we look at precise reasoning, we are generally choosing between two paths: formal mathematical theorem proving or brute-force runtime execution.
While theorem proving offers near-absolute mathematical certainty, execution is drastically easier to implement and fundamentally cheaper to run for massive, real-world systems. This cost difference is critical: relying on pure, deep-agent reasoning loops across million-line repositories is financially and computationally unsustainable, as frontier LLMs are simply too token-hungry to be used at scale, while remaining notoriously prone to hallucinations.
A new paper out of the National University of Singapore, introducing a system called CODE-AUGUR (Luo et al., 2026), serves as a perfect example of this pragmatic pattern to bypass these constraints. Instead of relying on an expensive LLM to implicitly guess where a vulnerability lives or burn tokens analyzing every possible code path, the architecture forces the LLM to suggest compact, explicit, in-source runtime invariants, and then uses a high-performance grey-box fuzzer as an unforgiving execution engine to filter and shatter those assumptions.
It represents a highly effective, "poor man's neurosymbolic" paradigm that achieves elite defensive security metrics at a fraction of the cost and token overhead of heavy verification.
01 From Bug Hunting to Specification Discovery
Software security has always been a fragile balance of power between attackers and defenders. However, autonomous LLM agents have drastically shifted the balance; an attacker with minimal expertise can now point a frontier agent at an open-source repository and rapidly harvest zero-day vulnerabilities.
If defenders merely replicate this workflow, using agents to scan code, find a bug, and patch it, they are playing a losing game. A single bug report is a transient, single-use artifact. It fixes one specific manifestation of an exploit but leaves the underlying, unwritten security principles unaddressed. As highlighted in the previous blog post, natural language prompts are inherently under-specified, forcing the underlying LLM to guess intent. When we build blindly on these guesses, we introduce structurally fragile gaps.
To reach parity with modern offensive tools, defenders must shift their core focus from vulnerability hunting to specification discovery. We must stop treating programming as writing explicit syntax and start viewing it as a journey across the Specification Spectrum.
02 A Bug Agents Can't See: The Little CMS Story
To understand why purely static AI audits fail, we only have to look at a motivating example from DARPA's AI Cyber Challenge (AIxCC): Little CMS, a widely used color-management library.
In this system, a vulnerability hides across a deeply fractured execution pipeline. During the construction phase, an attacker-controlled ICC profile enters the CreateTransform function. The function validates the user-supplied pixel format (PixelFormat) against the transformation's input color space (ColorSpace) via an internal guard function called IsProperColorSpace. Internally, this guard compares color models. Under standard circumstances, a matching color model logically implies a matching channel count, ensuring the safety of subsequent memory operations.
The validation looks completely sound on the surface. An LLM agent statically reading this code follows the plausible path, agrees with the structural logic, and marks the code as entirely secure.
But the agent misses a critical wildcard bypass. Within IsProperColorSpace, a special branch exists for the PT_ANY wildcard model. If an incoming profile carries this wildcard, the guard returns true directly without ever comparing the channel counts. This architectural blind spot allows a crafted malicious profile to force a massive divergence: setting fmt.channels = 13 while the library's internal entry color space implies cs.channels = 1. Because this mismatched metadata is stored silently as ordinary integers, nothing in the construction phase triggers an error or a sanitizer alert.
The trap springs much later during the execution phase. When a separate function, ApplyTransform, attempts to process the transaction, it routes the inflated pixel format into an internal utility called UnpackPixel. UnpackPixel reads the stored metadata and blindly executes a loop that iterates 13 times over a buffer provisioned for a standard 4-byte pixel, triggering an out-of-bounds read.
This causal chain is extraordinarily difficult for an AI agent to see because it spans two distinct runtime phases, multiple call layers, and entirely separate source files. Conversely, blind fuzzing alone also misses it. Satisfying a semi-valid profile that slips past early structural checks, injecting a mismatched channel count, and guiding execution into the deep sink of UnpackPixel presents a needle-in-a-haystack set of constraints. Because a grey-box fuzzer operates with semantic blindness, it has no idea that triggering the initial integer mismatch in the construction phase is an interesting or vulnerable state to prioritize. It receives no coverage feedback signal at the moment of corruption, so it abandons the path long before reaching the crash site.
03 The Poor Man's Neurosymbolic Loop
CODE-AUGUR implements a solution to this blind spot via an automated "Reason-Falsify-Refine" loop. Instead of keeping an AI agent's security reasoning hidden inside an ambiguous, unvalidated natural-language trajectory, the framework forces the model to put its money where its mouth is.
When the agent reviews a code component and deems it secure, it must explicitly state the local invariants, the mathematical or logical conditions, behind that judgment. CODE-AUGUR then durably commits these invariants directly into the project's source repository as executable assertions (e.g., assert(fmt.channels == cs.channels);).
Once the invariants are committed, the deterministic execution engine takes over. A grey-box fuzzer (like libFuzzer or Jazzer) targets the program. Crucially, the fuzzer's objective is inverted: instead of hunting for a generic system crash, it treats progress toward violating that specific assertion as its reward metric.
If the fuzzer triggers the assertion, it triggers a triage event:
On two benchmarks drawn from DARPA's AI Cyber Challenge and the OSV database, this loop finds 34%–370% more bugs than state-of-the-art agentic baselines including ATLANTIS, the AIxCC-winning cyber reasoning system, while running on widely available frontier models rather than a curated specialized one.
04 Fuzz the Spec, Not the Crash
Coverage-guided fuzzing chases breadth; invariant-guided fuzzing chases a property. CODE-AUGUR wires each invariant into the fuzzer's feedback mechanism so that approaching an invariant yields gradual, observable progress, using logarithmically sized range buckets and numeric distance metrics, rather than relying on basic edge count alone. The fuzzer treats progress toward an inconsistent state as highly interesting behavior and aggressively steers toward it.
The invariant also generalizes far beyond an isolated bug report. Due to its permanent placement in the source, the inferred Little CMS invariant automatically guards other, similar conversion functions present in the library that were never even explored by the initial testing harness. The exact same predicate can be automatically re-checked on symmetric output-format paths, entirely different entry points, and future revisions of the library, instantly alerting developers if a wildcard bypass is re-introduced.
This is the spec-as-artifact paradigm: the audit leaves behind reusable, durable knowledge, not just a passing CVE. Tying back to our under-specification thesis, specifications are the true, durable asset. A bug report merely captures one transient instance of a vulnerability, but a spec captures and paralyzes the overarching pattern of failure.
05 Fuzzing vs. Theorem Provers: Balancing Messy Reality
An alternative approach to validating these inferred properties would be to bypass execution entirely and feed the code and invariants directly into an SMT solver (like Z3) or a symbolic execution engine (like KLEE). Why opt for grey-box fuzzing instead?
The authors' design choices highlight a brutal systems engineering reality. Pure symbolic backends suffer from catastrophic state explosion when forced to evaluate large, real-world software. They routinely choke on pointer arithmetic, external network libraries, and complex file parsing. Fuzzing, by contrast, handles the "muddy exterior" of large production systems elegantly. By translating abstract logic into a shallow, concrete runtime target, CODE-AUGUR gives the fuzzer an accessible landmark to steer toward, bypassing the need to mathematically formalize the entire execution universe.
06 The Durability of Shallow Invariants
Manual inspection reveals that the properties recovered by current LLMs remain relatively shallow local invariants, such as integer bounds checks, array allocations, or data type constraints. We are not yet seeing AI generate deep, holistic architectural proofs. Yet, these shallow invariants are precisely the "dumb assumptions" that human developers consistently fail to write down, and they are incredibly durable.
The paper highlights a fascinating case study on the GPSD project. During its audit, CODE-AUGUR inferred a single semantic bound: the number of visible satellites must never exceed the receiver's array channel capacity (satellites_visible < MAXCHANNELS).
When a buffer overflow bug first emerged, human maintainers deployed a quick point-fix that clamped a loop in a single consumer function. Traditional sanitizers fell silent, appearing to validate the fix. However, because CODE-AUGUR's invariant constrained the global program state rather than a single access site, it immediately flagged that the fix was incomplete; roughly ten other producer drivers were still blindly copying raw packet values into the variable. Over the next four months, through a chain of subsequent remediations, that single inferred invariant repeatedly caught regressions and ultimately forced the developers to realize the array capacity itself was undersized.
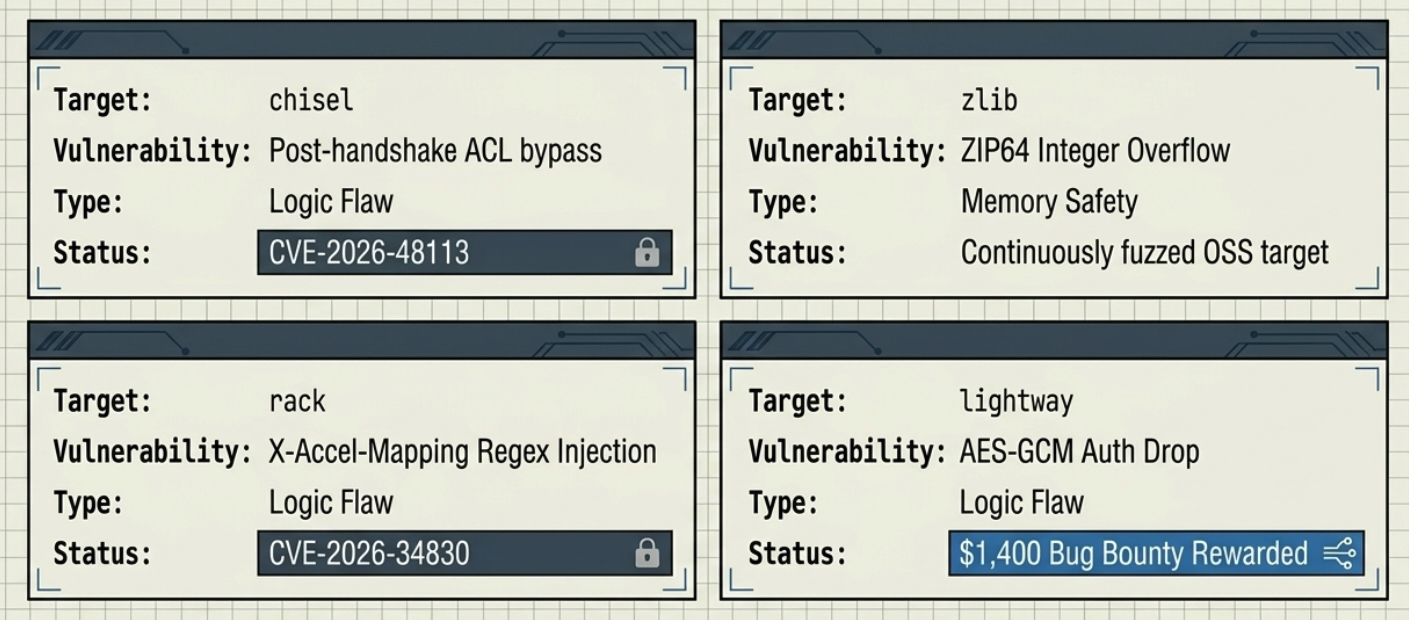
Beyond the benchmarks, CODE-AUGUR discovered 22 previously unknown vulnerabilities in widely used open-source projects, 16 of which have already been fixed or confirmed by developers, with several earning bug bounty rewards.
07 Open Questions
While the suggest-and-filter approach presents a highly practical design pattern, the authors are exceptionally candid about its fundamental boundaries. Moving from implicit assumptions to explicit execution loops uncovers several sharp bottlenecks that the field must resolve if it hopes to scale this architecture.
- The Semantic Invariant Trap: An assertion's quality is strictly bounded by the model's semantic grasp of the code. If an LLM completely misunderstands a complex functional component, the local invariants it commits will simply encode and cement that misunderstanding directly into the repository.
- The Triage Spiral: This loop is inherently bound by time and API budgets. When a fuzzer triggers a benign violation, the triage step relies on the agent to refine the assertion. If the model struggles to converge on the precise logic required, it can enter a costly, resource-draining spiral of iterative, incorrect refinements.
- The Threat Model Fragility: The very first step of the pipeline, distilling a coherent global threat model from messy markdown documentation and build files, is itself a single point of failure. If the initial scoping misses an attack surface, the downstream pipeline operates perfectly on entirely flawed parameters.
Beyond these direct tool-level boundaries lies a much more profound set of questions for automated program analysis.
- Can the inferred invariants ever truly compose into system-level guarantees? Right now, they remain stubbornly local. While an agent can constrain an integer overflow inside a specific parser loop, these micro-specifications do not automatically aggregate into holistic proofs of system soundness.
- We run headfirst into the boundary problem of under-specification. Even if you successfully verify a core computational kernel, it must ultimately interface with a muddy, unverified exterior: raw database operations, unvalidated JSON parsing libraries, and complex network layers. If the data validation layer at the edge of your specification boundary is brittle, the internal invariants can still be subverted, rendering the internal specification useless in production.
- Finally, there is a brutal cost vs. coverage trade-off. Running an independent fuzzing campaign with dedicated instrumentation counters for every single inferred invariant is computationally expensive at scale. It raises the binding constraint for the industry: Is the blocker model-scale (the ability of an LLM to hold massive context), or is it oracle-quality (our ability to accurately detect when an executed state has actually violated a deep security rule)?
Yet, despite these hurdles, the ultimate through-line of this research remains clear: the vulnerability discovery window is permanently collapsing.
The true value of this architectural evolution isn't the raw CVE count an AI agent can generate in a single weekend. It is the reality that automated audits now leave behind durable, checkable, in-source specifications rather than transient, one-off bug reports. By forcing the machine to write down its beliefs, we create a living test suite that continuously guards code long after the initial audit ends.
08 The Crucial Anchor: The Human in the Loop
While the suggest-and-filter pattern drastically optimizes token costs and shields the system from LLM hallucinations, it does not render the human security expert obsolete. In fact, it sharpens the value of their insight.
When time and budgets are limited, an automated agent cannot blindly wander a massive, multi-million-line codebase like Wireshark or systemd. One of the bottlenecks remains the initial setup: defining the global threat model, establishing trust boundaries, and scoping the problem down. It's entirely possible that future models will be better at threat modeling, but for now there appear to be limitations. If an AI agent receives an unconstrained or poorly mapped threat model, it will burn through resources generating functionally sound invariants for entirely irrelevant attack vectors.
The security expert's role shifts from that of a tedious line-by-line code inspector to a high-level architectural conductor. The human establishes the scope and boundaries of the playground; the automated reason-falsify-refine loop handles the exhausting grunt work of verification. As code increasingly writes itself, mastering this specification boundary is one of the ways defenders can keep up.
References
- Chin, A., Kim, D., Fu, Y.-F., Fleischer, F., Kim, Y., Han, H., Zhang, C., Lee, B. J., Zhao, H., & Kim, T. (2026). OSS-CRS: Liberating AIxCC cyber reasoning systems for real-world open-source security. arXiv preprint arXiv:2603.08566.
- Ding, H., Wang, Z., & Chen, H. (2026). FM-Agent: Scaling formal methods to large systems via LLM-based Hoare-style reasoning. arXiv preprint arXiv:2604.11556.
- Fioraldi, A., D'Elia, D., & Balzarotti, D. (2021). The use of likely invariants as feedback for fuzzers. Proceedings of the USENIX Security Symposium.
- Luo, Z., Zafar, M., Wolff, D., & Roychoudhury, A. (2026). CODE-AUGUR: Agentic vulnerability detection via specification inference. National University of Singapore. arXiv preprint arXiv:2606.18619.
- Ma, L., Liu, S., Li, Y., Xie, X., & Bu, L. (2025). Specgen: Automated generation of formal program specifications via large language models. Proceedings of the International Conference on Software Engineering (ICSE).
- Ruan, H., Zhang, Y., & Roychoudhury, A. (2025). SpecRover: Code Intent Extraction via LLMs. Proceedings of the International Conference on Software Engineering (ICSE).
- Team Atlanta. (2025). ATLANTIS: AI-driven threat localization, analysis, and triage intelligence system. arXiv preprint arXiv:2509.14589.
- Zhu, J., Shen, C., Li, Z., Yu, J., Chen, Y., & Pei, K. (2026). Locus: Agentic predicate synthesis for directed fuzzing. Proceedings of the International Conference on Software Engineering (ICSE).
* @topic fuzzing, LLMs, security
* @status published
*/