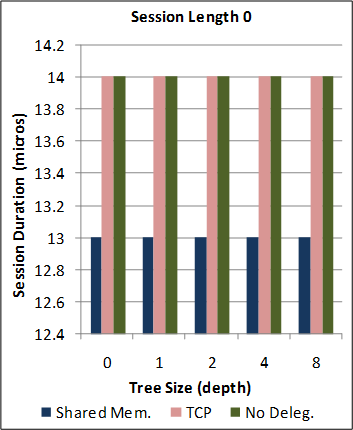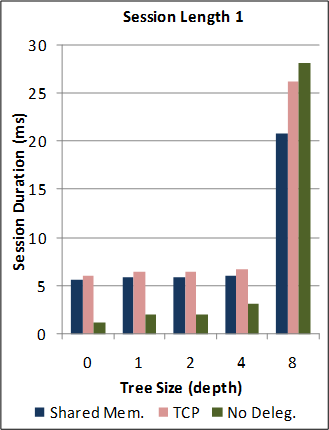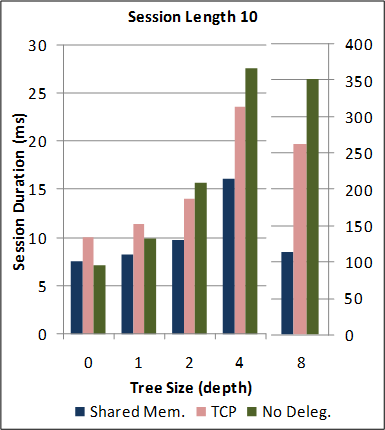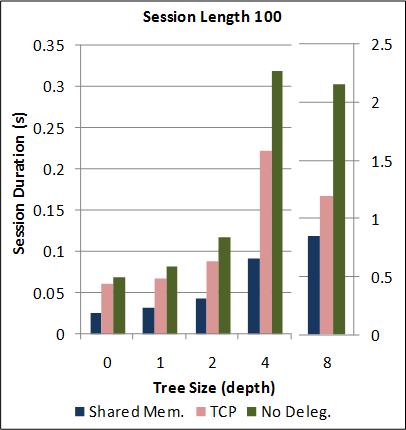
See Section 6 of the paper for a detailed description of the benchmark applications, experimental parameters, machine specifications and environment conditions.
Following are the complete results for the above benchmarks, including those omitted from the paper.
The full source code (including build and execution scripts) for Benchmarks 1, 2 and 3 is here: tar.gz.
The complete results (raw data sets) for Benchmarks 1, 2 and 3 are available here: tar.gz.
The source code for the parallel algorithm implementations are included in the application source package and in the main SJ distribution. The raw data from the macro benchmarks is available from here.
Back to the main page.
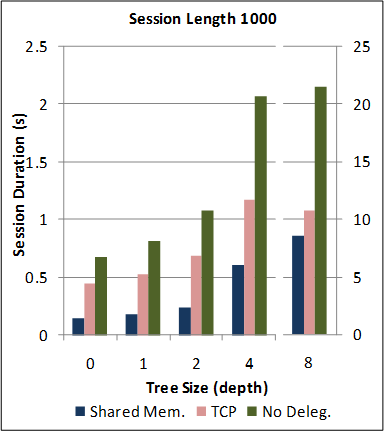
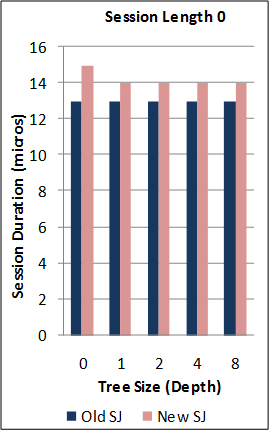
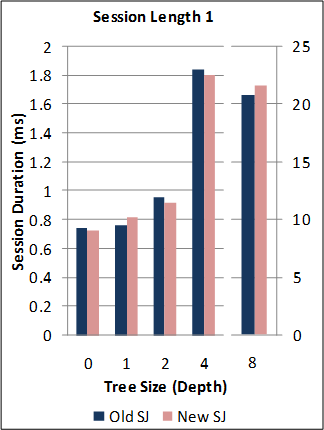
1-1. Performance of the new SJ Runtime with Abstract Transport framework against the preceding TCP-coupled SJ implementation.
Note: for this benchmark, the new SJ Runtime was configured to utilise the same wire protocol and message serialization format as the preceding SJ implementation (to directly measure the overheads due to the Abstract Transport mechanisms).
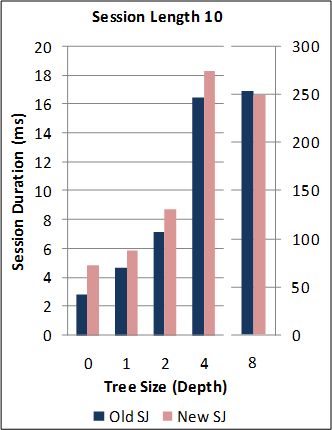
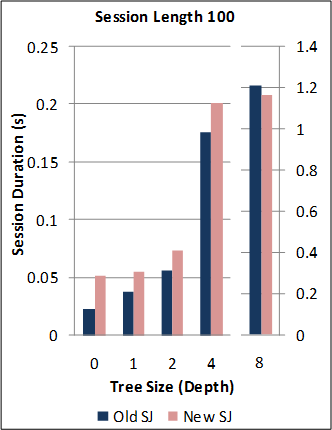
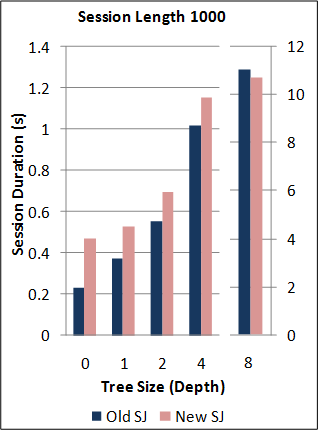
Back to the top (for benchmark source code and raw data files).
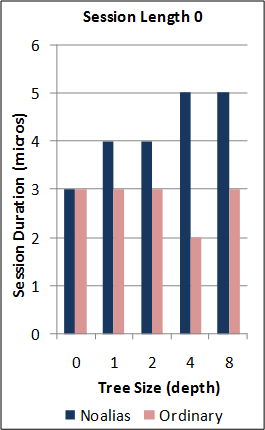
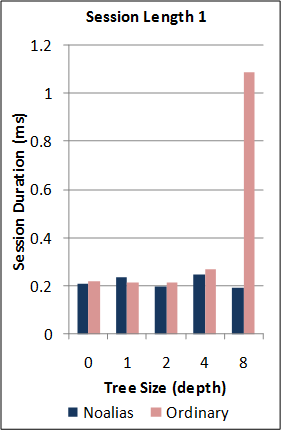
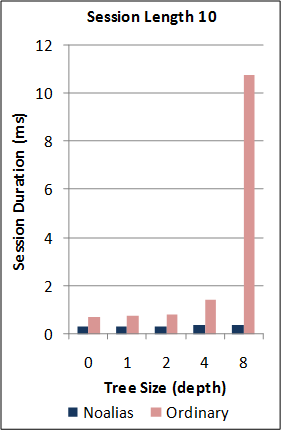
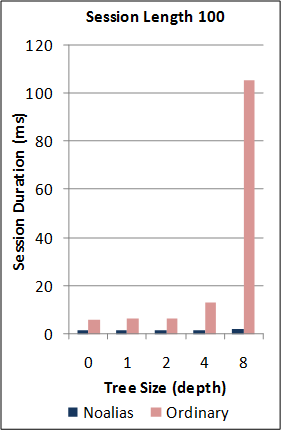
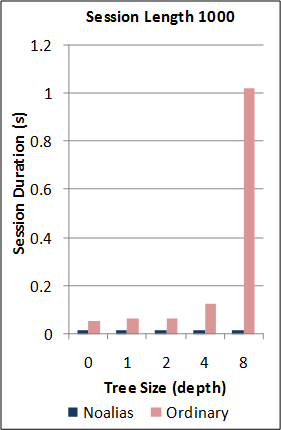
1-2. Performance of the new SJ Runtime against Java RMI.
*Note: the RMI benchmarks do not include the cost of the initial RMI registry lookup. Hence, no measurements are taken for RMI sessions of length 0. For this benchmark, the new SJ Runtime was configured to utilise a more optimal serialization component (different to above) for the communication of large binary tree messages.
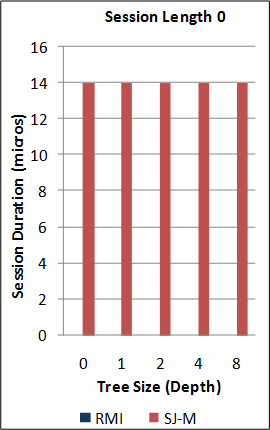 (See * above.)
(See * above.)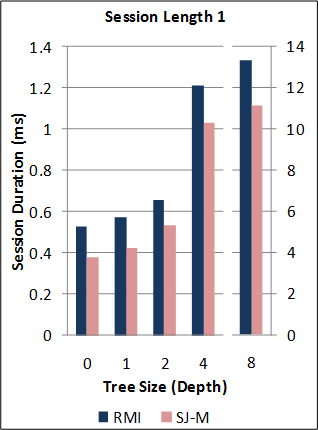
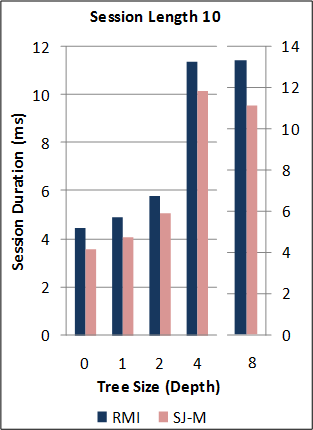
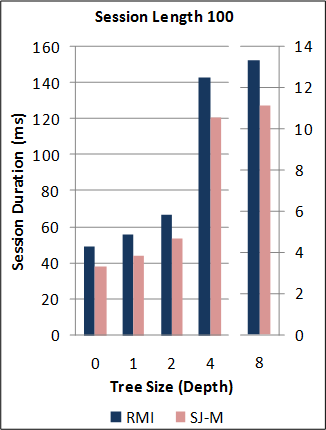
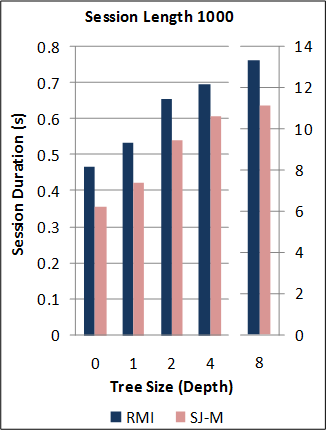
Back to the top (for benchmark source code and raw data files).
Back to the top (for benchmark source code and raw data files).
Back to the top (for benchmark source code and raw data files).
4. Macro benchmarks using parallel algorithm implementations.
Please see here for implementation details and the complete benchmark results for the parallel Jacobi and n-Body algorithms.