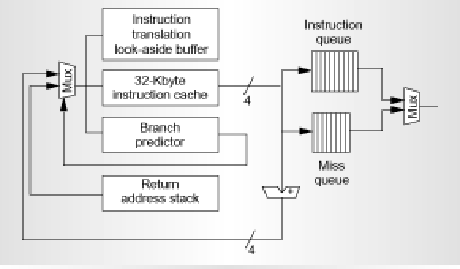
Address fetch happens in stage A. Also, during this stage there is a
32-byte buffer that supports sequential prefetching into the instruction
cache. This is very useful, as when we have a cache miss, we request
32 bytes, but instead of requesting 32 bytes as needed by the cache, the
processor requests that 64 bytes be brought in. The first 32 bytes are
filled into the instruction cache and the next 32 bytes are stored in the
buffer. The cache can use the buffer to get the next instruction if the
next sequential cache line is also a miss.
The branch predictor used here is a 16-K 2 bit up/down saturating counter,
Gshare predictor. This is a very very large predictor, which has a lot of
entries, which means more overhead to access the entries. While this might
give us better prediction, we might incur more latency while trying to get
the values out of the predictor, but the tradeoff pays off as a better
predictor with a little extra latency is much better compared to a
predictor that does not do a good job of prediction, as the branch
misprediction penalties are quite large. The scheme offsets the history bits
such that the three lower-order index bits that index into the predictor
use information from the PC only.
As mentioned earlier, with a very high pipeline depth, branch mispredictions can be very costly. They can have as much as a 8 cycle penalty. The problem is taken care of by buffering the instructions. There are two instruction buffering queues in the UltraSPARC-III; the instruction queue and the miss queue. The fetch unit predicts the path of execution and keeps filling up the instruction queue until it's full. The four-entry miss queue contains the sequential instructions which would be executed in case the branch is not taken. In the event of a branch misprediction, there are instructions already present in the miss queue, and can be sent to the execution units for processing.