|
|
|
March 2003 |
|
Paul H J Kelly |
|
|
|
These lecture notes are partly based on the
course text, Hennessy and Patterson’s Computer Architecture, a quantitative
approach (3rd ed), and on the lecture slides of David Patterson,
John Kubiatowicz and Yujia Jin at Berkeley (CS252, Jan 2001) |
|
|
|
|
|
|
|
|
Why add another processor? |
|
How should they be connected – I/O, memory bus,
L2 cache, registers? |
|
Cache coherency – the problem |
|
Coherency – what are the rules? |
|
Coherency using broadcast – update/invalidate |
|
Coherency using multicast – SMP vs ccNUMA |
|
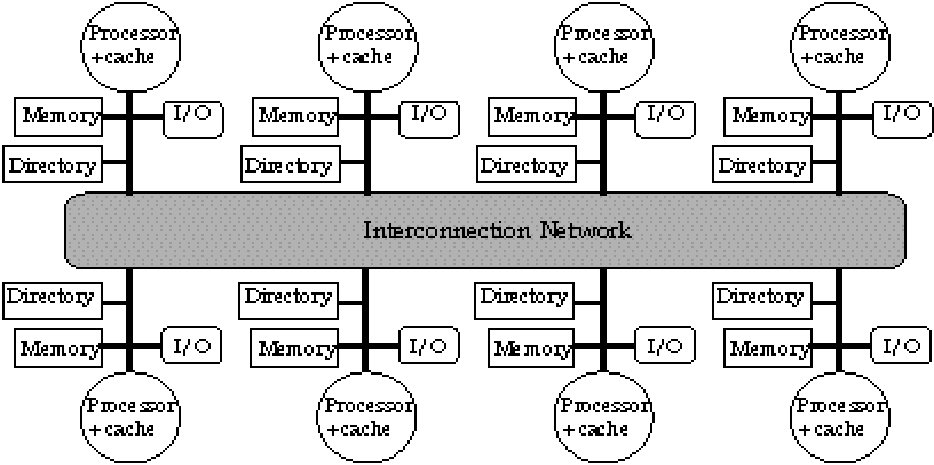
Distributed directories, home nodes, ownership;
the ccNUMA design space |
|
Beyond ccNUMA; COMA and Simple COMA |
|
Hybrids and clusters |
|
|
|
|
|
|
64 nodes, Compaq Alpha EV67 21264A processor |
|
High Performance Interconnect via Quadrics Elan
III NICs |
|
Linux |
|
Programmed using MPI (“Message passing
interface”) |
|
Small configuration installed at Imperial’s
Parallel Computing Centre for fluid dynamics research |
|
|
|
|
|
|
144 eight-processor SMP High Nodes perform the
primary compute functions. |
|
12 two-processor SMP High Nodes perform service
functions. |
|
1,152 Power3 processors in the compute nodes run
at 375 MHz. Each processor has a peak performance of 1.500 Mflops (millions
of floating-point operations per second) |
|
576 gigabytes of total system memory, at 4 GB
per compute node |
|
5.1 terabytes -- 5,100 gigabytes -- of
associated disk |
|
|
|
|
1024-CPU system consisting of two 512-CPU SGI
Origin 3800 systems. Peak performance of 1 TFlops (1012 floating
point operations) per second.
500MHz R14000 CPUs organized in 256 4-CPU nodes |
|
1 TByte of RAM. 10 TByte of on-line storage
& 100 TByte near-line storage |
|
45 racks, 32 racks containing CPUs &
routers, 8 I/O racks & 5 racks for disks |
|
Each 512-CPU machine offers application program
a single, shared memory image |
|
|
|
|
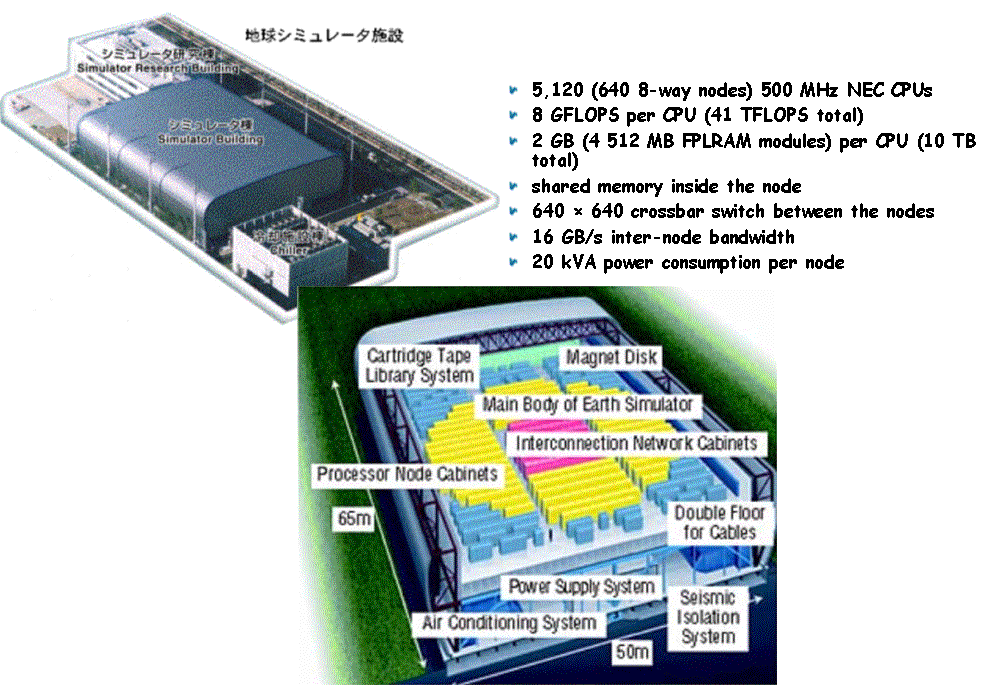
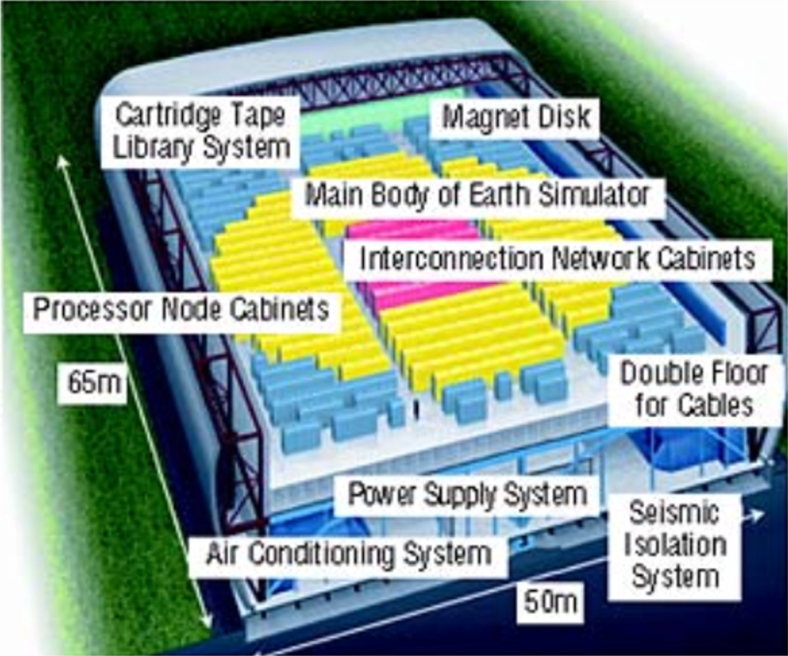
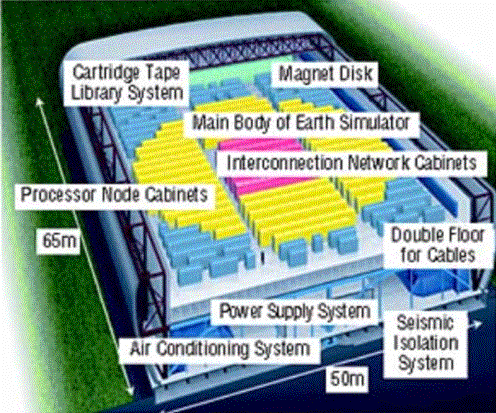
5,120 (640 8-way nodes) 500 MHz NEC CPUs |
|
8 GFLOPS per CPU (41 TFLOPS total) |
|
2 GB (4 512 MB FPLRAM modules) per CPU (10 TB
total) |
|
shared memory inside the node |
|
640 × 640 crossbar switch between the nodes |
|
16 GB/s inter-node bandwidth |
|
20 kVA power consumption per node |
|
|
|
|
|
|
|
Executing loops in parallel |
|
Improve performance of single application |
|
Barrier synchronisation at end of loop |
|
Iteration i of loop 2 may read data produced by
iteration i of loop 1 – but perhaps also from other iterations |
|
Example: NaSt3DGP |
|
High-throughput servers |
|
Eg. database, transaction processing, web
server, e-commerce |
|
Improve performance of single application |
|
Consists of many mostly-independent transactions |
|
Sharing data |
|
Synchronising to ensure consistency |
|
Transaction roll-back |
|
Mixed, multiprocessing workloads |
|
|
|
|
|
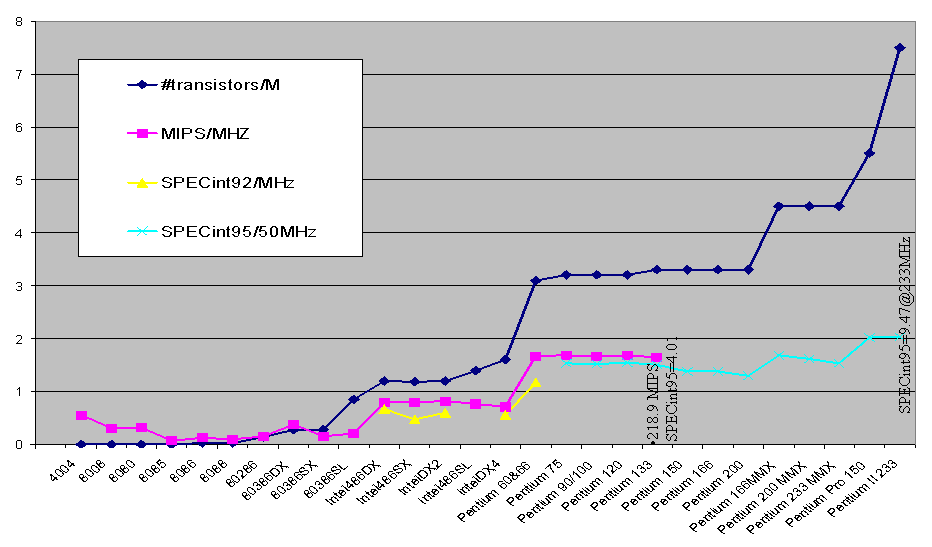
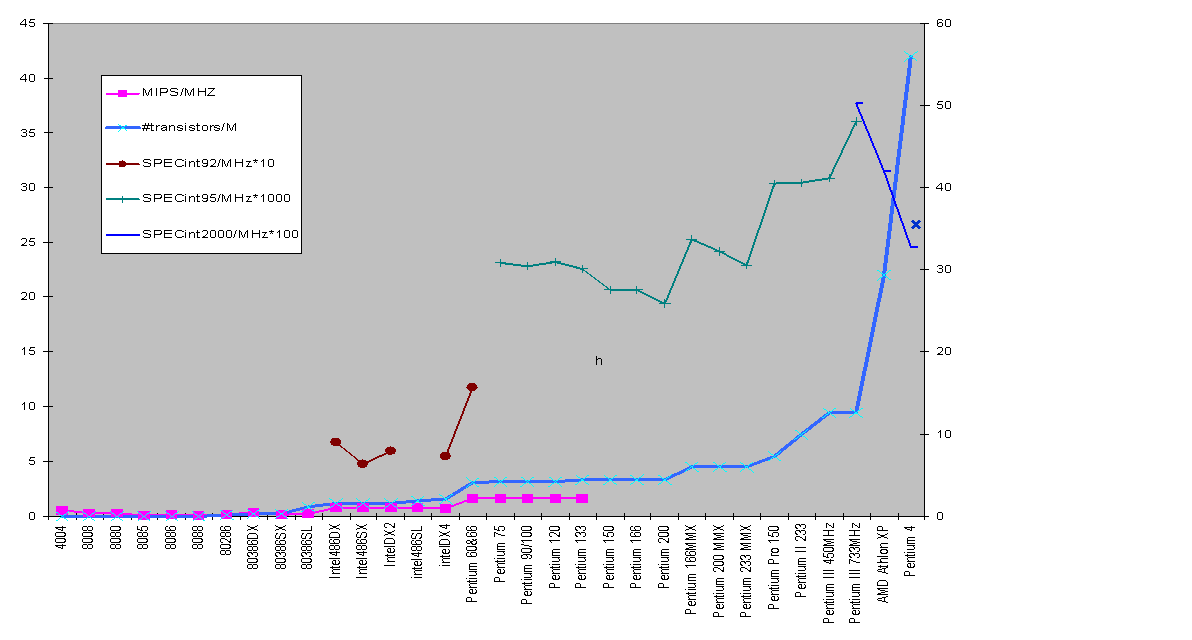
Increasing the complexity of a single CPU leads
to diminishing returns |
|
Due to lack of instruction-level parallelism |
|
Too many simultaneous accesses to one register
file |
|
Forwarding wires between functional units too
long - inter-cluster communication takes >1 cycle |
|
|
|
|
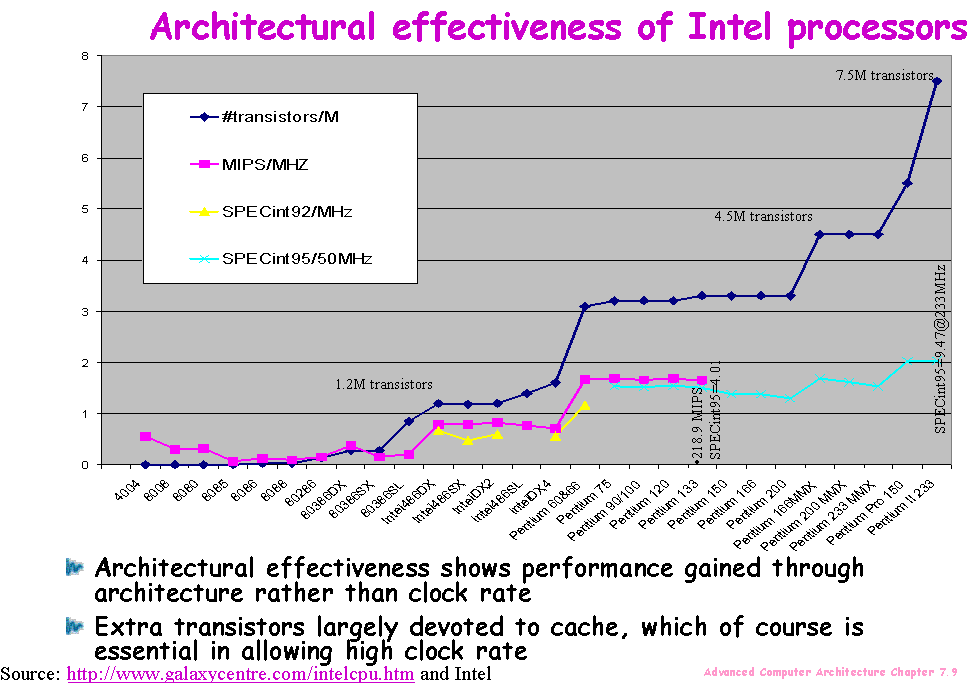
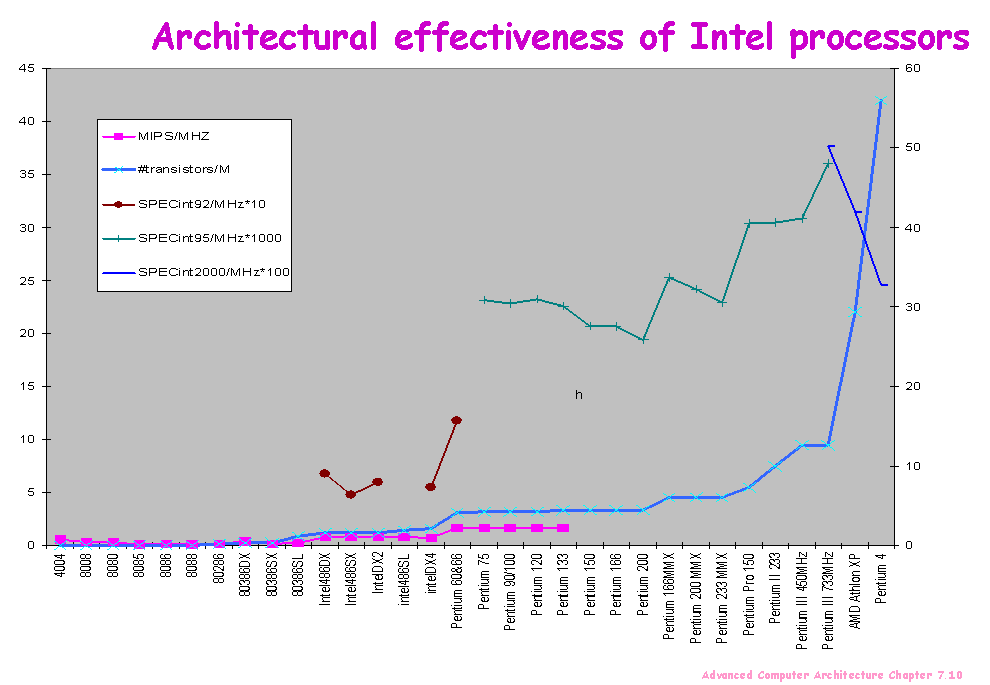
Architectural effectiveness shows performance
gained through architecture rather than clock rate |
|
Extra transistors largely devoted to cache,
which of course is essential in allowing high clock rate |
|
|
|
|
|
|
|
|
|
Idea: instead of trying to exploit more
instruction-level parallelism by building a bigger CPU, build two - or more |
|
This only makes sense if the application
parallelism exists… |
|
Why might it be better? |
|
No need for multiported register file |
|
No need for long-range forwarding |
|
CPUs can take independent control paths |
|
Still need to synchronise and communicate |
|
Program has to be structured appropriately… |
|
|
|
|
|
|
|
|
|
How should the CPUs be connected? |
|
Idea: systems linked by network connected via
I/O bus |
|
Eg Fujitsu AP3000, Myrinet, Quadrics |
|
Idea: CPU/memory packages linked by network
connecting main memory units |
|
Eg SGI Origin |
|
Idea: CPUs share main memory |
|
Eg Intel Xeon SMP |
|
Idea: CPUs share L2/L3 cache |
|
Eg IBM Power4 |
|
Idea: CPUs share L1 cache |
|
Idea: CPUs share registers, functional units |
|
Cray/Tera MTA (multithreaded architecture),
Symmetric multithreading (SMT), as in Hyperthreaded Pentium 4, Alpha 21464,
etc |
|
|
|
|
|
Tradeoffs: |
|
close coupling to minimise delays incurred when
processors interact |
|
separation to avoid contention for shared
resources |
|
Result: |
|
spectrum of alternative approaches based on
application requirements, cost, and packaging/integration issues |
|
Currently: |
|
just possible to integrate 2 full-scale CPUs on
one chip together with large shared L2 cache |
|
common to link multiple CPUs on same motherboard
with shared bus connecting to main memory |
|
more aggressive designs use richer
interconnection network, perhaps with cache-to-cache transfer capability |
|
|
|
|
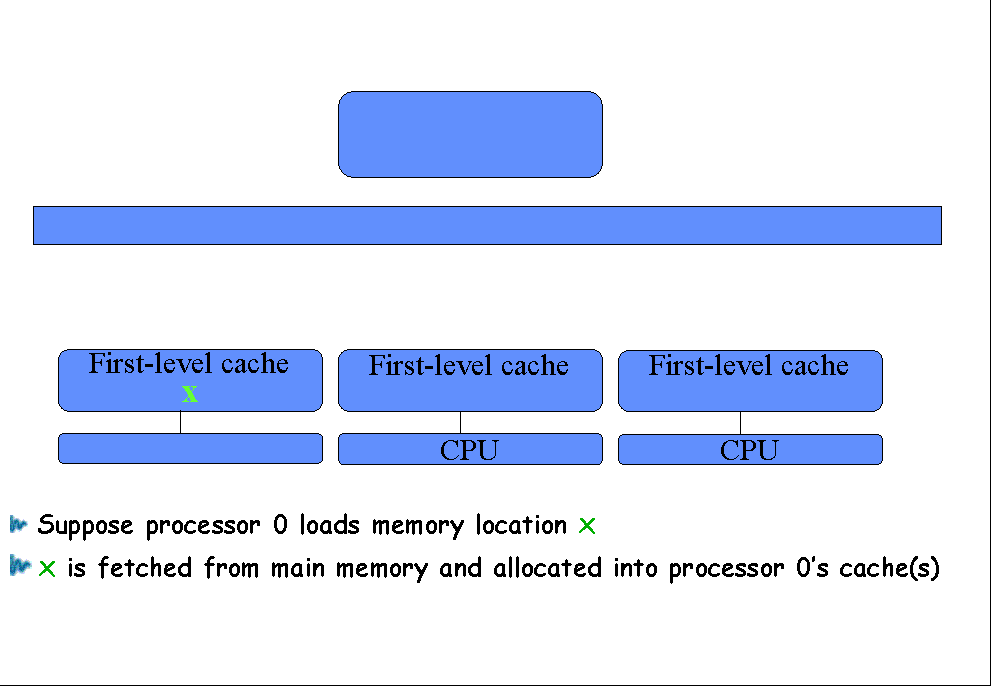
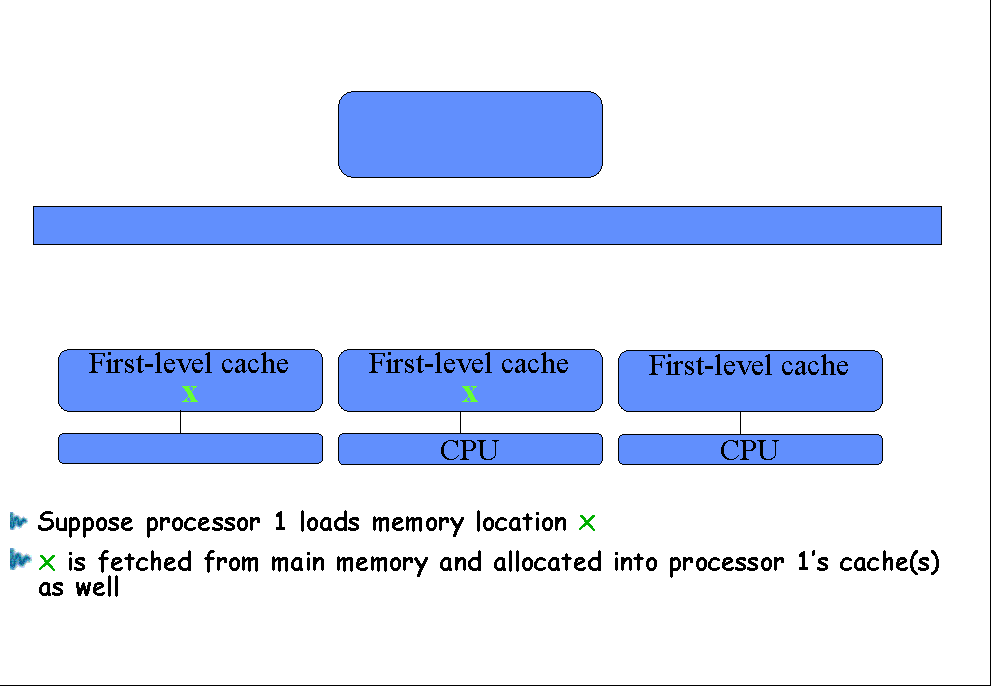
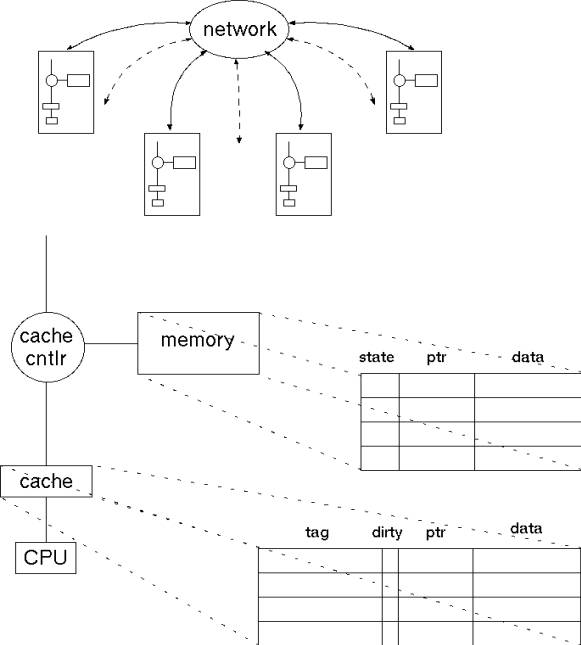
Suppose processor 0 loads memory location x |
|
x is fetched from main memory and allocated into
processor 0’s cache(s) |
|
|
|
|
Suppose processor 1 loads memory location x |
|
x is fetched from main memory and allocated into
processor 1’s cache(s) as well |
|
|
|
|
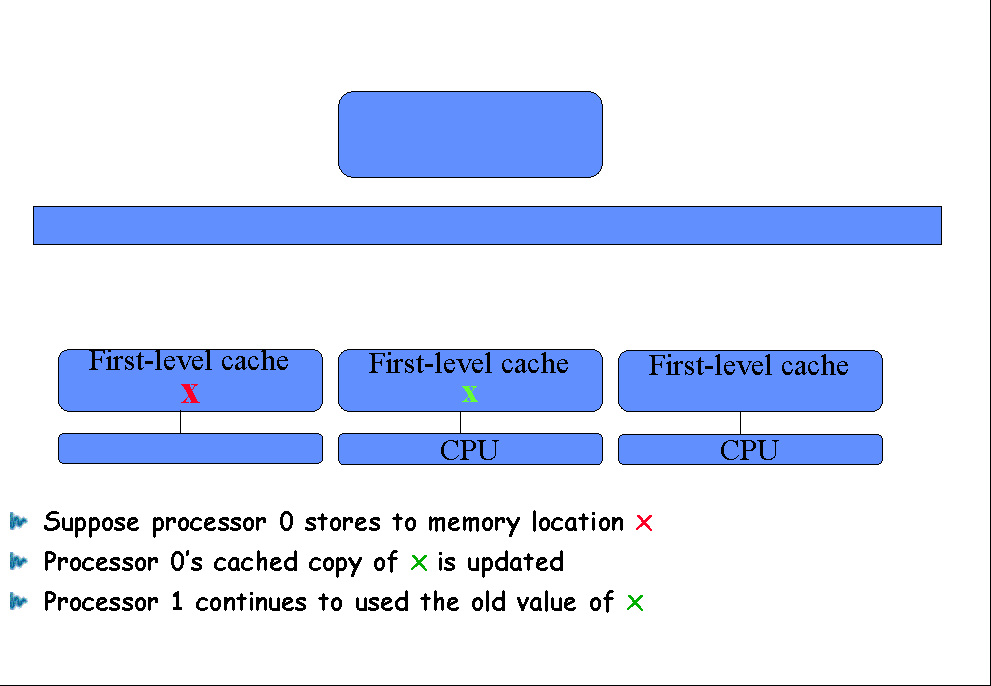
Suppose processor 0 stores to memory location x |
|
Processor 0’s cached copy of x is updated |
|
Processor 1 continues to used the old value of x |
|
|
|
|
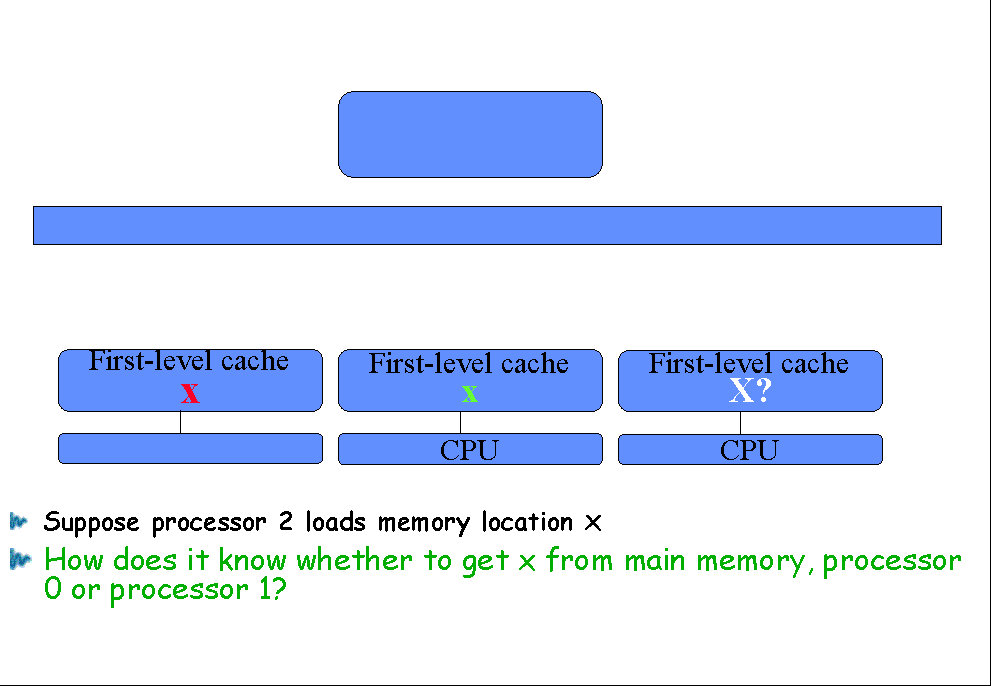
Suppose processor 2 loads memory location x |
|
How does it know whether to get x from main
memory, processor 0 or processor 1? |
|
|
|
|
Two issues: |
|
How do you know where to find the latest version
of the cache line? |
|
How do you know when you can use your cached
copy – and when you have to look for a more up-to-date version? |
|
|
|
We will find answers to this after first
thinking about what a distributed shared memory implementation is supposed
to do… |
|
|
|
|
|
|
|
|
Goal (?): |
|
“Processors should not continue to use
out-of-date data indefinitely” |
|
Goal (?): |
|
“Every load instruction should yield the result
of the most recent store to that address” |
|
Goal (?):
(definition: Sequential Consistency) |
|
“the result of any execution is the same as if
the operations of all the processors were executed in some sequential
order, and the operations of each individual processor appear in this
sequence in the order specified by its program” |
|
(Leslie Lamport, “How to make a multiprocessor
computer that correctly executes multiprocess programs” (IEEE Trans
Computers Vol.C-28(9) Sept 1979) |
|
|
|
|
|
Idea #1: when a store to address x occurs, update
all the remote cached copies |
|
To do this we need either: |
|
To broadcast every store to every remote cache |
|
Or to keep a list of which remote caches hold
the cache line |
|
Or at least keep a note of whether there are any
remote cached copies of this line |
|
But first…how well does this update idea work? |
|
|
|
|
|
Problems with update |
|
What about if the cache line is several words
long? |
|
Each update to each word in the line leads to a
broadcast |
|
What about old data which other processors are
no longer interested in? |
|
We’ll keep broadcasting updates indefinitely… |
|
Do we really have to broadcast every store? |
|
It would be nice to know that we have exclusive
access to the cacheline so we don’t have to broadcast updates… |
|
|
|
|
|
Suppose instead of updating remote cache lines,
we invalidate them all when a store occurs? |
|
After the first write to a cache line we know
there are no remote copies – so subsequent writes don’t lead to
communication |
|
Is invalidate always better than update? |
|
Often |
|
But not if the other processors really need the
new data as soon as possible |
|
Note that to exploit this, we need a bit on each
cache line indicating its sharing state |
|
(analogous to write-back vs write-through) |
|
|
|
|
Update: |
|
May reduce latency of subsequent remote reads |
|
if any are made |
|
Invalidate: |
|
May reduce network traffic |
|
e.g. if same CPU writes to the line before
remote nodes take copies of it |
|
|
|
|
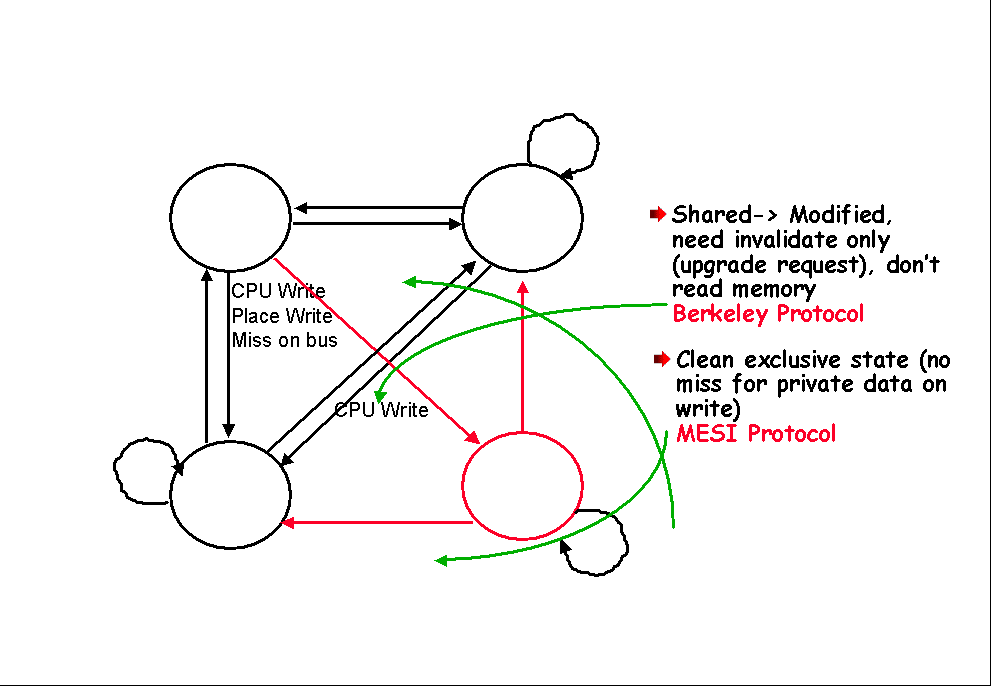
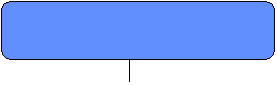
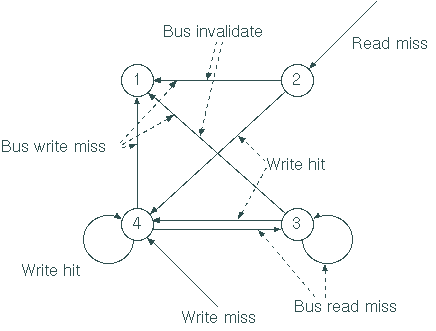
Four cache line states: |
|
|
|
Broadcast invalidations on bus unless cache line
is exclusively “owned” (DIRTY) |
|
|
|
|
1. INVALID |
|
2. VALID: clean, potentially shared, unowned |
|
3. SHARED-DIRTY: modified, possibly shared, owned |
|
4. DIRTY: modified, only copy, owned |
|
|
|
|
|
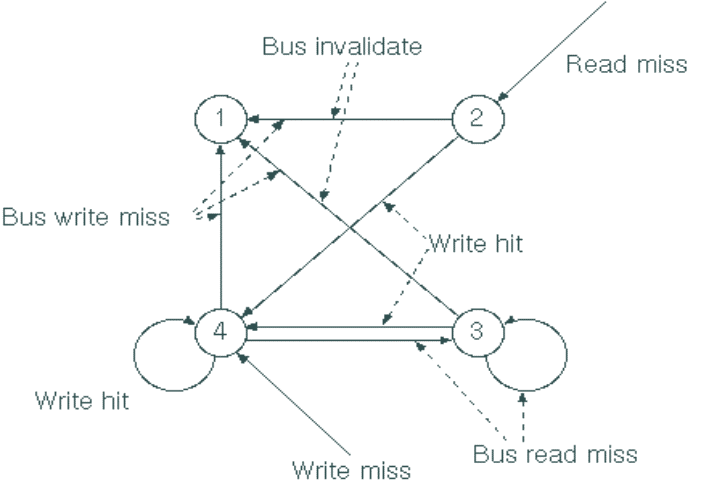
The protocol state transitions are implemented
by the cache controller – which “snoops” all the bus traffic |
|
Transitions are triggered either by |
|
the bus (Bus invalidate, Bus write miss, Bus
read miss) |
|
The CPU (Read hit, Read miss, Write hit, Write
miss) |
|
|
|
For every bus transaction, it looks up the
directory (cache line state) information for the specified address |
|
If this processor holds the only valid data
(DIRTY), it responds to a “Bus read miss” by providing the data to the
requesting CPU |
|
If the memory copy is out of date, one of the
CPUs will have the cache line in the SHARED-DIRTY state (because it updated
it last) – so must provide data to requesting CPU |
|
State transition diagram doesn’t show what
happens when a cache line is displaced… |
|
|
|
|
|
|
|
|
|
Invalidate is usually better than update |
|
Cache line state “DIRTY” bit records whether
remote copies exist |
|
If so, remote copies are invalidated by
broadcasting message on bus – cache controllers snoop all traffic |
|
Where to get the up-to-date data from? |
|
Broadcast read miss request on the bus |
|
If this CPUs copy is DIRTY, it responds |
|
If no cache copies exist, main memory responds |
|
If several copies exist, the CPU which holds it
in “SHARED-DIRTY” state responds |
|
If a SHARED-DIRTY cache line is displaced, …
need a plan |
|
How well does it work? |
|
See extensive analysis in Hennessy and Patterson |
|
|
|
|
|
Extensions: |
|
Fourth State: Ownership |
|
|
|
|
|
|
|
|
|
|
Write Races: |
|
Cannot update cache until bus is obtained |
|
Otherwise, another processor may get bus first,
and then write the same cache block! |
|
Two step process: |
|
Arbitrate for bus |
|
Place miss on bus and complete operation |
|
If miss occurs to block while waiting for bus,
handle miss (invalidate may be needed) and then restart. |
|
Split transaction bus: |
|
Bus transaction is not atomic:
can have multiple outstanding transactions for a block |
|
Multiple misses can interleave,
allowing two caches to grab block in the Exclusive state |
|
Must track and prevent multiple misses for one
block |
|
Must support interventions and invalidations |
|
|
|
|
|
|
Multiple processors must be on bus, access to
both addresses and data |
|
Add a few new commands to perform coherency,
in addition to read and write |
|
Processors continuously snoop on address bus |
|
If address matches tag, either invalidate or
update |
|
Since every bus transaction checks cache tags,
could interfere with CPU just to check: |
|
solution 1: duplicate set of tags for L1 caches just
to allow checks in parallel with CPU |
|
solution 2: L2 cache already duplicate,
provided L2 obeys inclusion with
L1 cache |
|
block size, associativity of L2 affects L1 |
|
|
|
|
Bus serializes writes, getting bus ensures no
one else can perform memory operation |
|
On a miss in a write back cache, may have the
desired copy and it’s dirty, so must reply |
|
Add extra state bit to cache to determine shared
or not |
|
Add 4th state (MESI) |
|
|
|
|
|
Bus inevitably becomes a bottleneck when many processors
are used |
|
Use a more general interconnection network |
|
So snooping does not work |
|
DRAM
memory is also distributed |
|
Each
node allocates space from local DRAM |
|
Copies
of remote data are made in cache |
|
Major design issues: |
|
How to find and represent the “directory"
of each line? |
|
How to find a copy of a line? |
|
As a case study, we will look at S3.MP (Sun's Scalable
Shared memory Multi-Processor, a CC-NUMA (cache-coherent non-uniform memory
access) architecture |
|
|
|
|
|
Separate Memory per Processor |
|
Local or Remote access via memory controller |
|
1 Cache Coherency solution: non-cached pages |
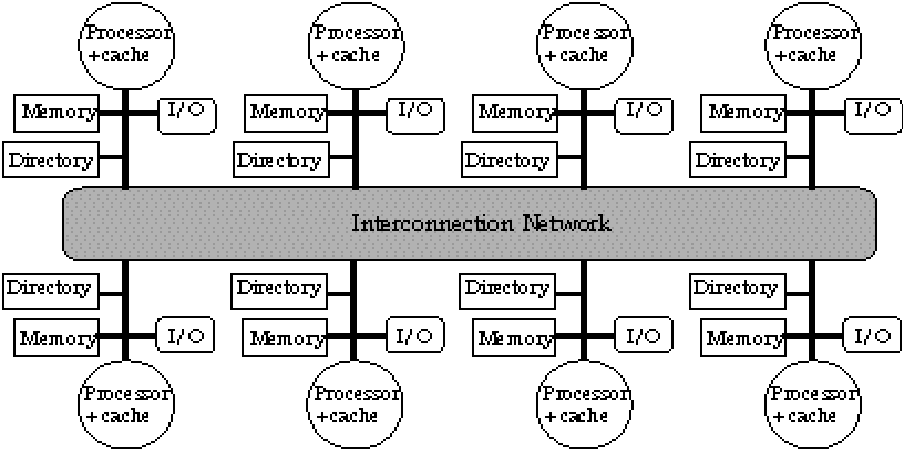
|
Alternative: directory per cache that tracks
state of every block in every cache |
|
Which caches have a copies of block, dirty vs.
clean, ... |
|
Info per memory block vs. per cache block? |
|
PLUS: In memory => simpler protocol
(centralized/one location) |
|
MINUS: In memory => directory is ƒ(memory
size) vs. ƒ(cache size) |
|
Prevent directory as bottleneck?
distribute directory entries with memory, each keeping track of which
Procs have copies of their blocks |
|
|
|
|
|
|
|
Similar to Snoopy Protocol: Three states |
|
Shared: ≥ 1 processors have data, memory
up-to-date |
|
Uncached (no processor hasit; not valid in any
cache) |
|
Exclusive: 1 processor (owner) has data;
memory out-of-date |
|
In addition to cache state, must track which
processors have data when in the shared state (usually bit vector, 1 if
processor has copy) |
|
Keep it simple(r): |
|
Writes to non-exclusive data
=> write miss |
|
Processor blocks until access completes |
|
Assume messages received
and acted upon in order sent |
|
|
|
|
|
No bus and don’t want to broadcast: |
|
interconnect no longer single arbitration point |
|
all messages have explicit responses |
|
Terms: typically 3 processors involved |
|
Local node where a request originates |
|
Home node where the memory location
of an address resides |
|
Remote node has a copy of a cache
block, whether exclusive or shared |
|
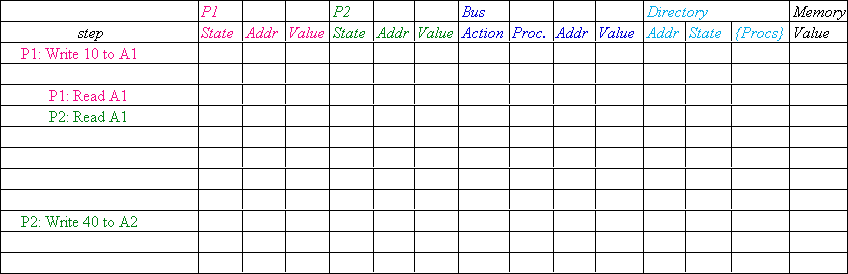
Example messages on next slide:
P = processor number, A = address |
|
|
|
|
|
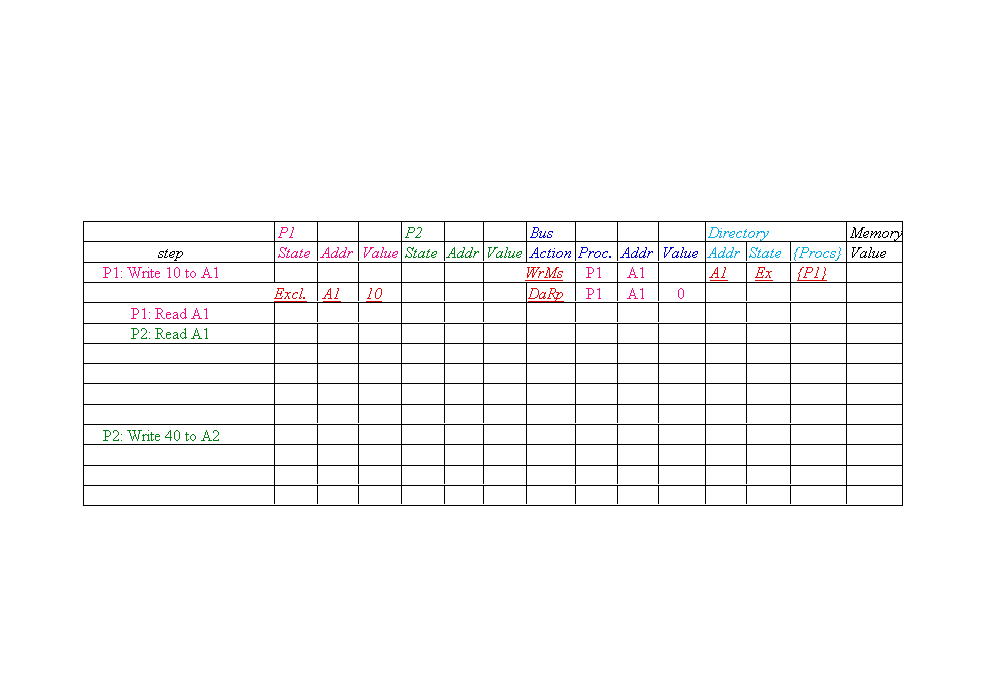
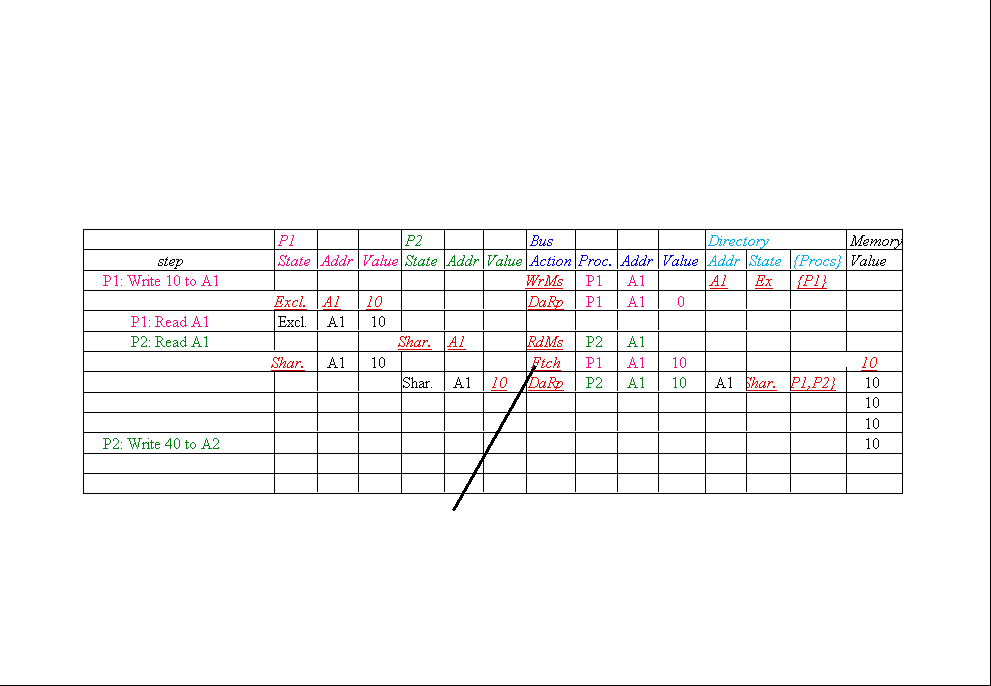
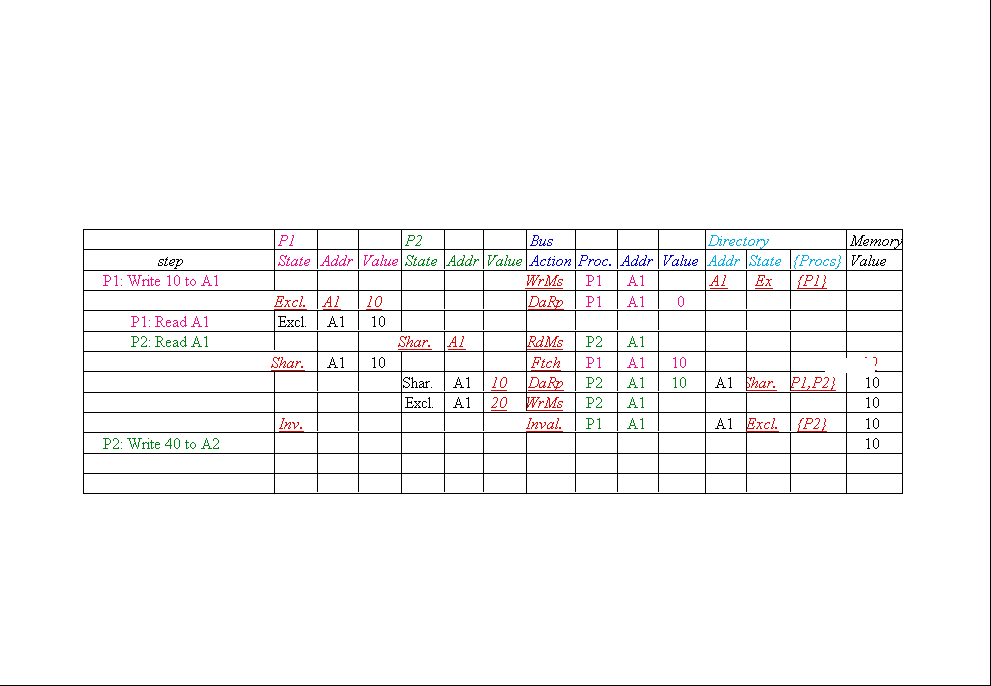
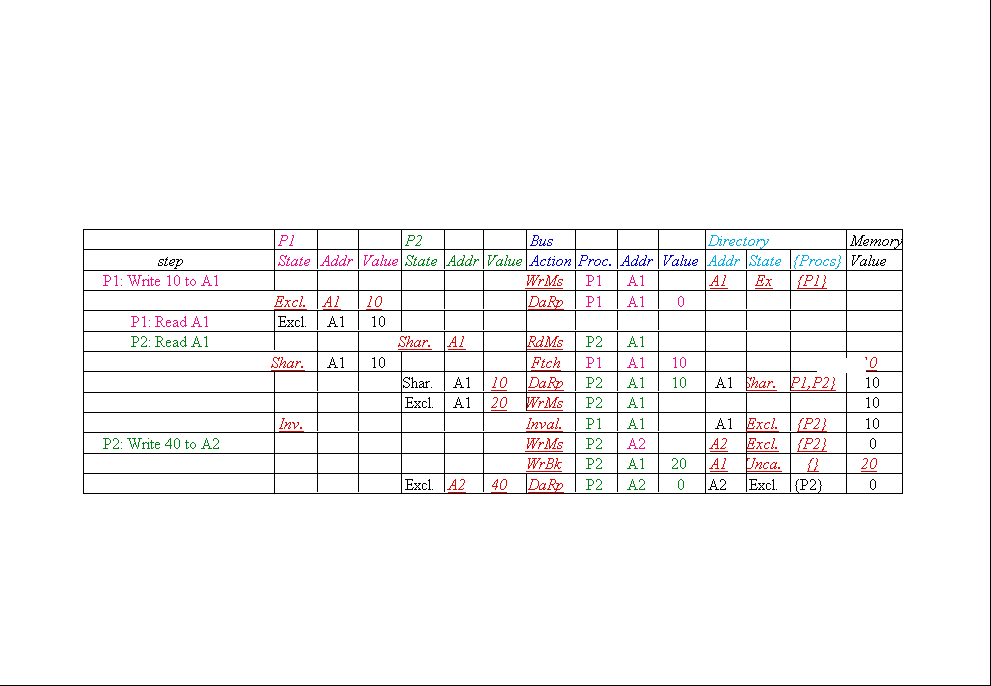
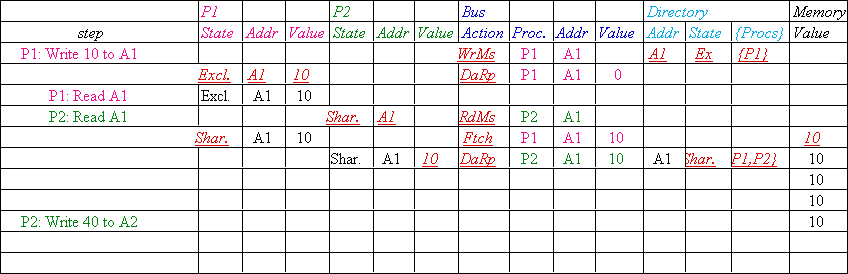
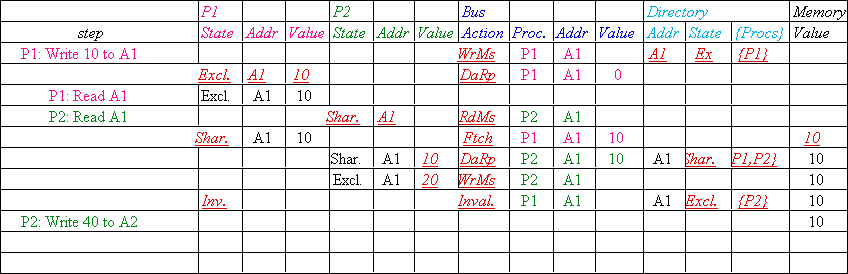
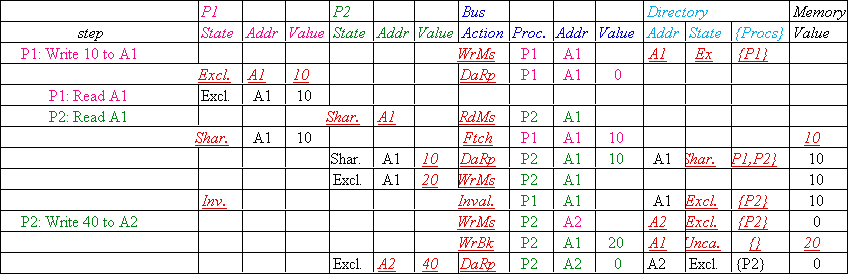
Message type Source Destination Msg
Content |
|
Read miss Local cache Home directory P,
A |
|
Processor P reads data at address A;
make P a read sharer and arrange to send data back |
|
Write miss Local cache Home directory
P, A |
|
Processor P writes data at address A;
make P the exclusive owner and arrange to send data back |
|
Invalidate Home directory Remote caches A |
|
Invalidate a shared copy at address A. |
|
Fetch Home directory Remote cache A |
|
Fetch the block at address A and send it to its
home directory |
|
Fetch/Invalidate Home directory Remote
cache A |
|
Fetch the block at address A and send it to its
home directory; invalidate the block in the cache |
|
Data value reply Home directory Local
cache Data |
|
Return a data value from the home memory (read
miss response) |
|
Data write-back Remote cache Home
directory A, Data |
|
Write-back a data value for address A
(invalidate response) |
|
|
|
|
|
|
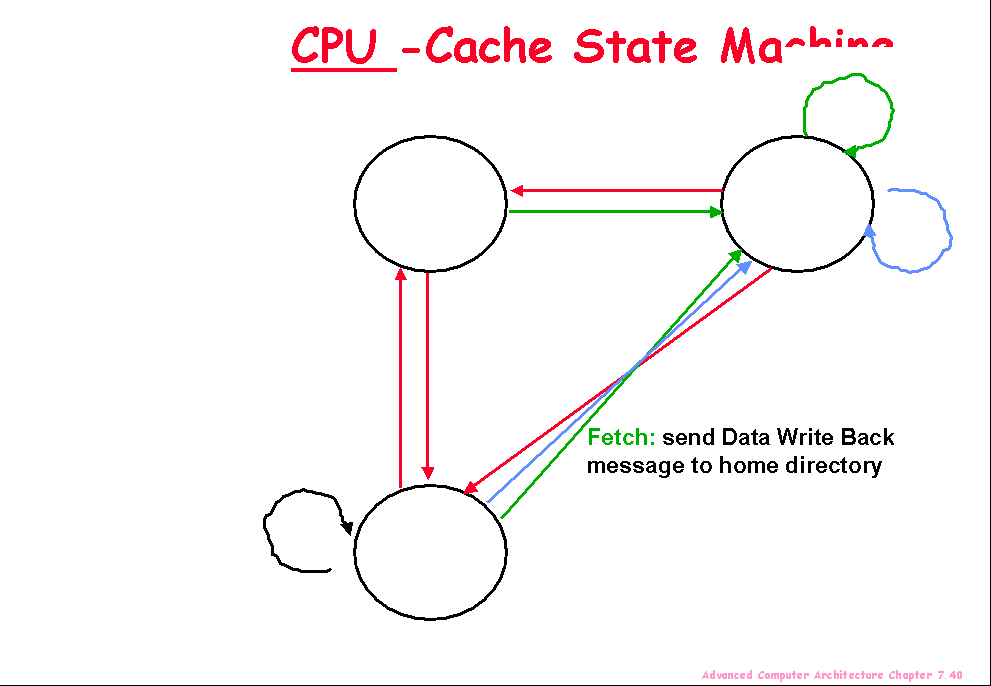
States identical to snoopy case; transactions
very similar. |
|
Transitions caused by read misses, write misses,
invalidates, data fetch requests |
|
Generates read miss & write miss msg to home
directory. |
|
Write misses that were broadcast on the bus for
snooping => explicit invalidate & data fetch requests. |
|
Note: on a write, a cache block is bigger, so
need to read the full cache block |
|
|
|
|
State machine
for CPU requests
for each
memory
block |
|
Invalid state
if in
memory |
|
|
|
|
Same states & structure as the transition
diagram for an individual cache |
|
2 actions: update of directory state & send
msgs to statisfy requests |
|
Tracks all copies of memory block. |
|
Also indicates an action that updates the
sharing set, Sharers, as well as sending a message. |
|
|
|
|
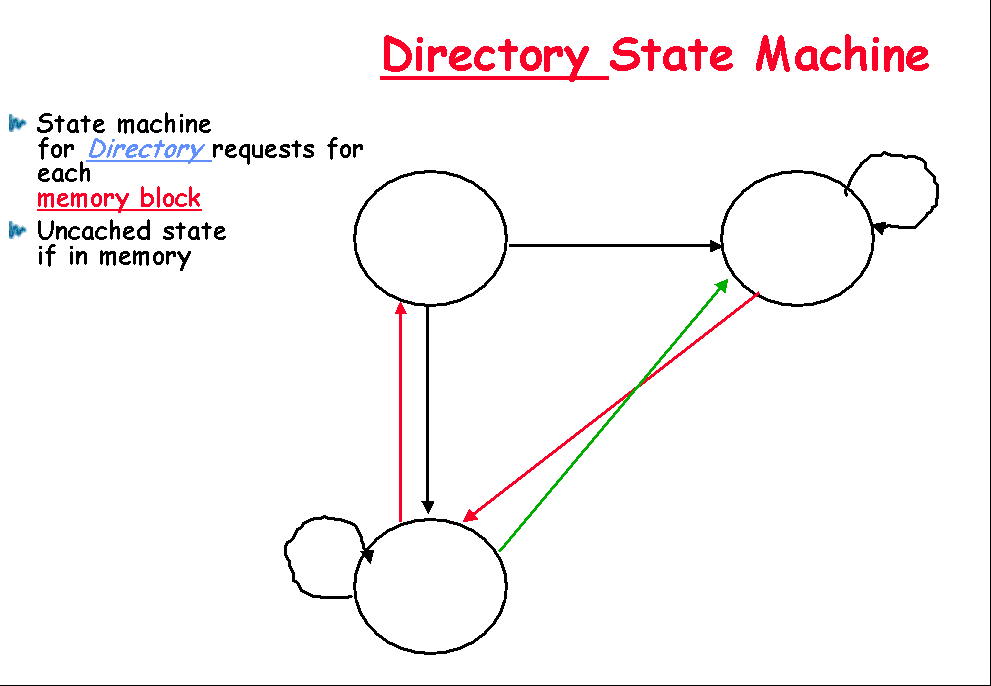
State machine
for Directory requests
for each
memory block |
|
Uncached state
if in memory |
|
|
|
|
|
Message sent to directory causes two actions: |
|
Update the directory |
|
More messages to satisfy request |
|
Block is in Uncached state: the copy in memory
is the current value; only possible requests for that block are: |
|
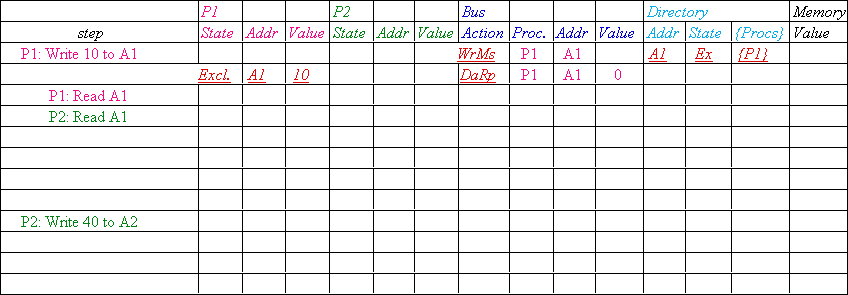
Read miss: requesting processor sent data from
memory &requestor made only sharing node; state of block made Shared. |
|
Write miss: requesting processor is sent the
value & becomes the Sharing node. The block is made Exclusive to
indicate that the only valid copy is cached. Sharers indicates the identity
of the owner. |
|
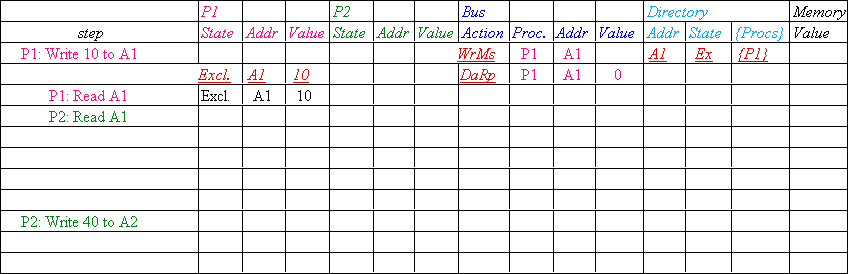
Block is Shared => the memory value is
up-to-date: |
|
Read miss: requesting processor is sent back the
data from memory & requesting processor is added to the sharing set. |
|
Write miss: requesting processor is sent the
value. All processors in the set Sharers are sent invalidate messages,
& Sharers is set to identity of requesting processor. The state of the
block is made Exclusive. |
|
|
|
|
|
Block is Exclusive: current value of the block
is held in the cache of the processor identified by the set Sharers (the
owner) => three possible directory requests: |
|
Read miss: owner processor sent data fetch
message, causing state of block in owner’s cache to transition to Shared
and causes owner to send data to directory, where it is written to memory
& sent back to requesting processor.
Identity of requesting
processor is added to set Sharers, which still contains the identity of the
processor that was the owner (since it still has a readable copy). State is shared. |
|
Data write-back: owner processor is replacing
the block and hence must write it back, making memory copy up-to-date
(the home directory essentially becomes the owner), the block is now
Uncached, and the Sharer set is empty. |
|
Write miss: block has a new owner. A message is
sent to old owner causing the cache to send the value of the block to the
directory from which it is sent to the requesting processor, which becomes
the new owner. Sharers is set to identity of new owner, and state of block
is made Exclusive. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
We assume operations atomic, but they are not;
reality is much harder; must avoid deadlock when run out of bufffers in
network (see Appendix E) |
|
|
|
Optimizations: |
|
read miss or write miss in Exclusive: send data
directly to requestor from owner vs. 1st to memory and then from memory to
requestor |
|
|
|
|
|
Why Synchronize? Need to know when it is safe
for different processes to use shared data |
|
|
|
Issues for Synchronization: |
|
Uninterruptable instruction to fetch and update
memory (atomic operation); |
|
User level synchronization operation using this
primitive; |
|
For large scale MPs, synchronization can be a
bottleneck; techniques to reduce contention and latency of synchronization |
|
|
|
|
|
|
Atomic exchange: interchange a value in a
register for a value in memory |
|
0 => synchronization variable is free |
|
1 => synchronization variable is locked and
unavailable |
|
Set register to 1 & swap |
|
New value in register determines success in
getting lock |
|
0 if you succeeded in setting the lock (you were
first) |
|
1 if other processor had already claimed access |
|
Key is that exchange operation is indivisible |
|
Test-and-set: tests a value and sets it if the
value passes the test |
|
Fetch-and-increment: it returns the value of a
memory location and atomically increments it |
|
0 => synchronization variable is free |
|
|
|
|
|
Hard to have read & write in 1 instruction:
use 2 instead |
|
Load linked (or load locked) + store conditional |
|
Load linked returns the initial value |
|
Store conditional returns 1 if it succeeds (no
other store to same memory location since preceeding load) and 0 otherwise |
|
Example doing atomic swap with LL & SC: |
|
try: mov R3,R4 ; mov exchange value
ll R2,0(R1) ;
load linked
sc R3,0(R1) ; store conditional
beqz R3,try ;
branch store fails (R3 = 0)
mov R4,R2 ; put
load value in R4 |
|
Example doing fetch & increment with LL
& SC: |
|
try: ll R2,0(R1) ; load
linked
addi R2,R2,#1 ; increment (OK if reg–reg)
sc R2,0(R1)
; store conditional
beqz R2,try ; branch
store fails (R2 = 0) |
|
|
|
|
|
Spin locks: processor continuously tries to
acquire, spinning around a loop trying to get the lock |
|
li R2,#1
lockit: exch R2,0(R1) ;atomic exchange
bnez R2,lockit ;already locked? |
|
|
|
What about MP with cache coherency? |
|
Want to spin on cache copy to avoid full memory
latency |
|
Likely to get cache hits for such variables |
|
Problem: exchange includes a write, which
invalidates all other copies; this generates considerable bus traffic |
|
Solution: start by simply repeatedly reading the
variable; when it changes, then try exchange (“test and test&set”): |
|
try: li R2,#1
lockit: lw R3,0(R1) ;load var
bnez R3,lockit ;not free=>spin
exch R2,0(R1) ;atomic exchange
bnez R2,try ;already locked? |
|
|
|
|
|
What is consistency? When must a processor see
the new value? e.g., seems that |
|
P1: A = 0; P2: B = 0; |
|
..... ..... |
|
A = 1; B = 1; |
|
L1: if (B == 0) ... L2: if (A
== 0) ... |
|
Impossible
for both if statements L1 & L2 to be true? |
|
What if write invalidate is delayed &
processor continues? |
|
Memory consistency models:
what are the rules for such cases? |
|
Sequential consistency: result of any execution
is the same as if the accesses of each processor were kept in order and the
accesses among different processors were interleaved => assignments
before ifs above |
|
SC: delay all memory accesses until all
invalidates done |
|
|
|
|
|
Weak consistency schemes offer faster execution
than sequential consistency |
|
Not really an issue for most programs;
they are synchronized |
|
A program is synchronized if all access to
shared data are ordered by synchronization operations |
|
write (x)
...
release (s) {unlock}
...
acquire (s)
{lock}
...
read(x) |
|
Only those programs willing to be
nondeterministic are not synchronized: “data race”: outcome f(proc. speed) |
|
Several Relaxed Models for Memory Consistency
since most programs are synchronized; characterized by their attitude
towards: RAR, WAR, RAW, WAW
to different addresses |
|
|
|
|
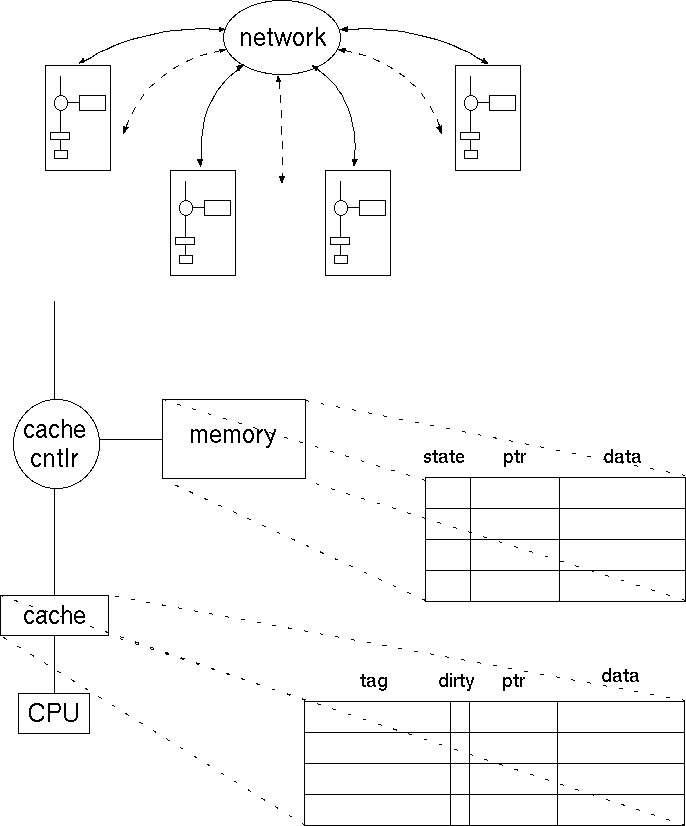
Caches contain all information on state of
cached memory blocks |
|
Snooping and Directory Protocols similar; bus
makes snooping easier because of broadcast (snooping => uniform memory
access) |
|
Directory has extra data structure to keep track
of state of all cache blocks |
|
Distributing directory => scalable shared
address multiprocessor
=> Cache coherent, Non uniform memory access |
|
|
|
|
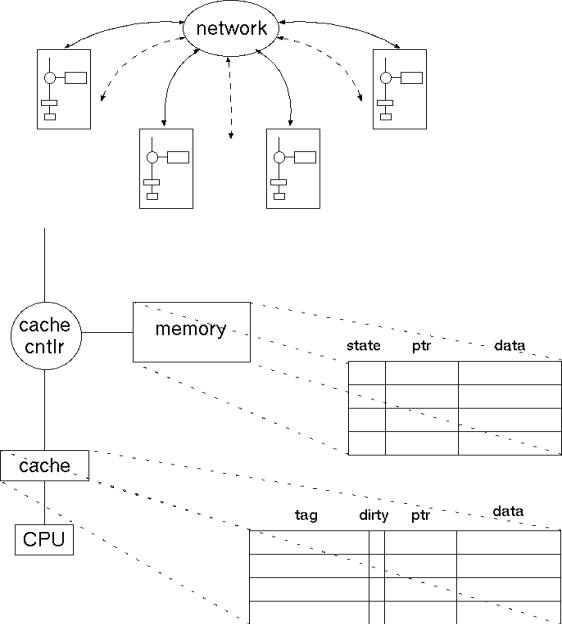
Protocol Basics |
|
S3.MP uses distributed singly-linked sharing
lists, with static homes |
|
|
|
Each line has a “home" node, which stores
the root of the directory |
|
|
|
Requests are sent to the home node |
|
|
|
Home either has a copy of the line, or knows a node
which does |
|
|
|
|
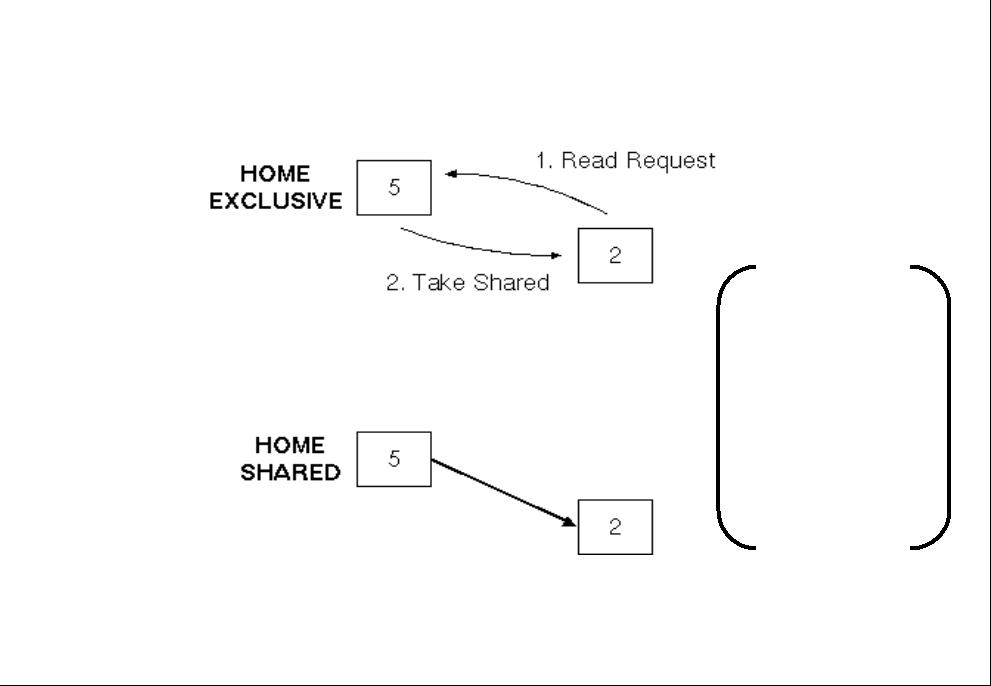
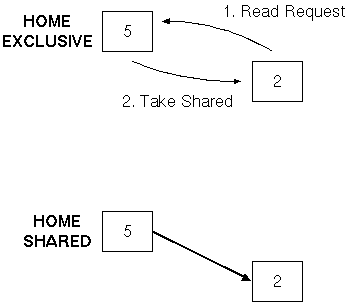
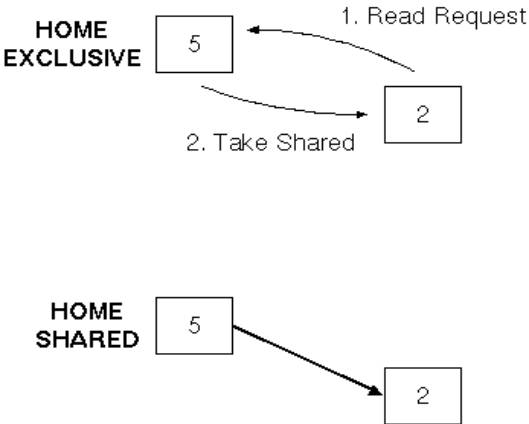
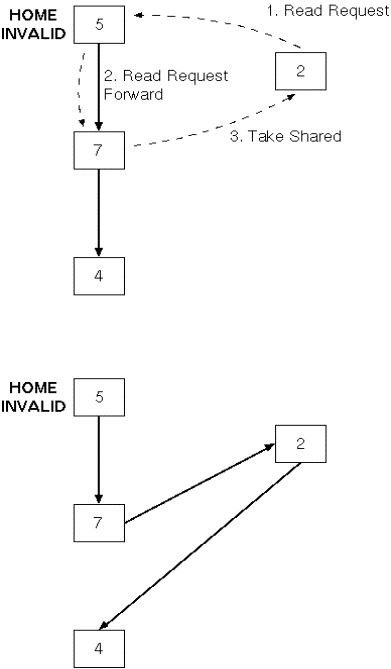
Simple case: initially only the home has the
data: |
|
|
|
|
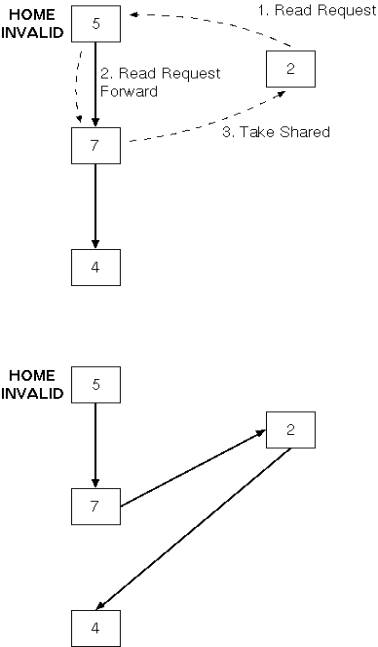
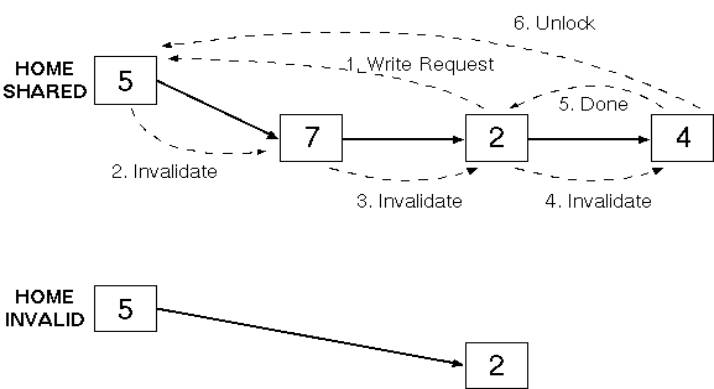
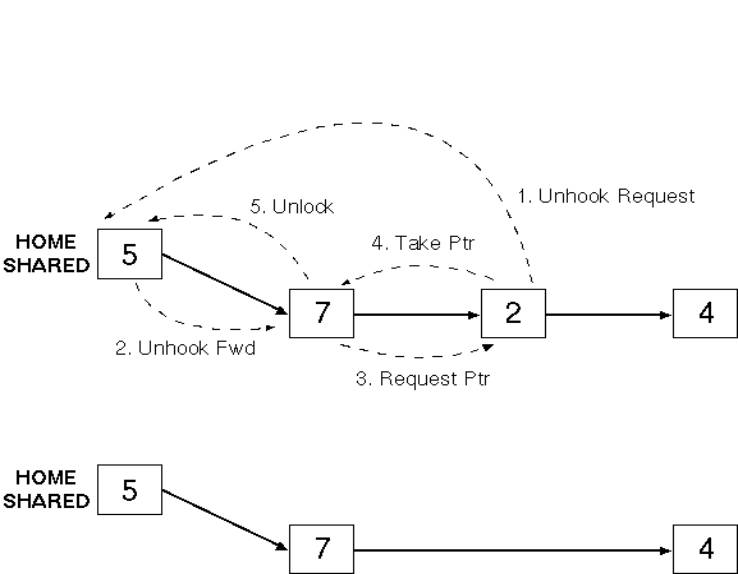
More interesting case: some other processor has
the data |
|
|
|
|
|
|
|
|
|
|
|
|
|
Home passes request to first processor in chain,
adding requester into the sharing list |
|
|
|
|
|
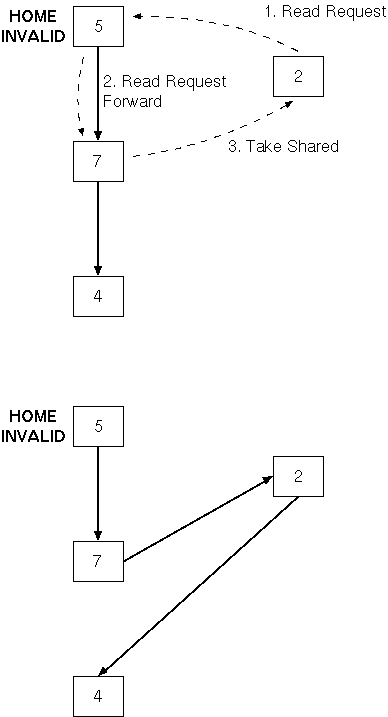
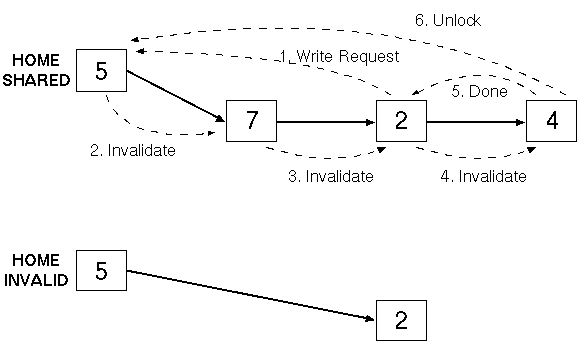
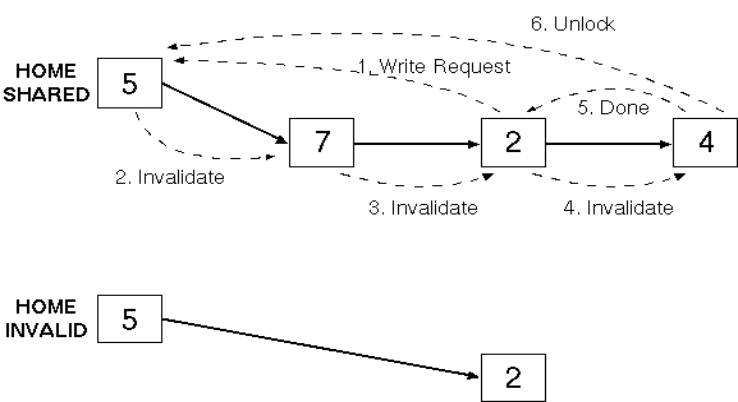
If the line is exclusive (i.e. dirty bit is set)
no message is required |
|
Else send a write-request to the home |
|
Home sends an invalidation message down the chain |
|
Each copy is invalidated (other than that of the
requester) |
|
Final node in chain acknowledges the requester and
the home |
|
Chain is locked for the duration of the invalidation |
|
|
|
|
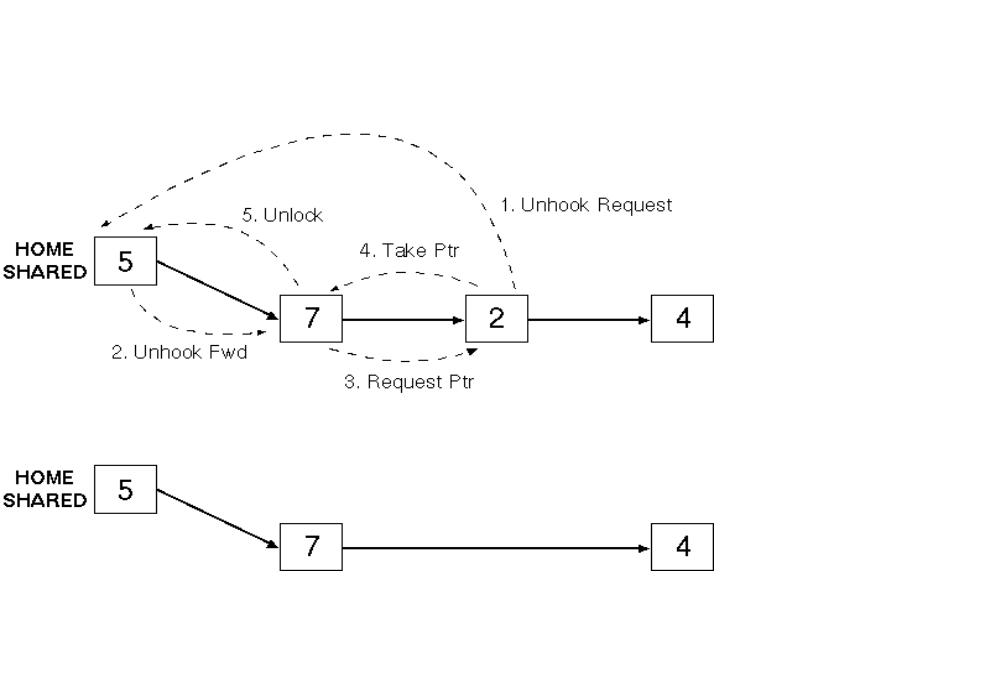
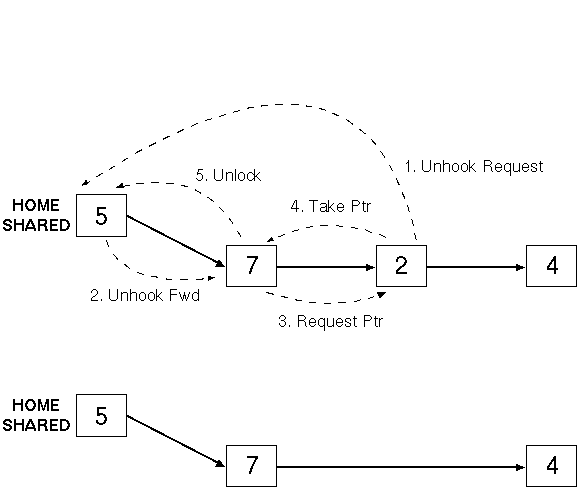
When a read or write requires a line to be
copied into the cache from another node, an existing line may need to be replaced |
|
Must remove it from the sharing list |
|
Must not lose last copy of the line |
|
|
|
|
|
How does a CPU find a valid copy of a specified
address’s data? |
|
Translate virtual address to physical |
|
Physical address includes bits which identify
“home” node |
|
Home node is where DRAM for this address resides |
|
But current valid copy may not be there – may be
in another CPU’s cache |
|
Home node holds pointer to sharing chain, so
always knows where valid copy can be found |
|
|
|
|
|
|
S3MP’s cache coherency protocol implements
strong consistency |
|
Many recent designs implement a weaker
consistency model… |
|
S3MP uses a singly-linked sharing chain |
|
Widely-shared data – long chains – long
invalidations, nasty replacements |
|
“Widely shared data is rare” |
|
In real life: |
|
IEEE Scalable Coherent Interconnect (SCI):
doubly-linked sharing list |
|
SGI Origin 2000: bit vector sharing list |
|
Real Origin 2000 systems in service with 256
CPUs |
|
Sun E10000: hybrid multiple buses for
invalidations, separate switched network for data transfers |
|
Many E10000s in service, often with 64 CPUs |
|
|
|
|
|
COMA: cache-only memory architecture |
|
Data migrates into local DRAM of CPUs where it
is being used |
|
Handles very large working sets cleanly |
|
Replacement from DRAM is messy: have to make
sure someone still has a copy |
|
Scope for interesting OS/architecture hybrid |
|
System slows down if total memory requirement
approaches RAM available, since space for replication is reduced |
|
Examples: DDM, KSR-1/2, rumours from IBM… |
|
|
|
|
|
L1 cache is already very busy with CPU traffic |
|
L2 cache also very busy… |
|
L3 cache doesn’t always have the current value
for a cache line |
|
Although L1 cache is normally write-through, L2
is normally write-back |
|
Some data may bypass L3 (and perhaps L2) cache
(eg when stream-prefetched) |
|
In Power4, cache controller manages L2 cache –
all external invalidations/requests |
|
L3 cache improves access to DRAM for accesses
both from CPU and from network |
|
|
|
|
Caches are essential to gain the maximum performance
from modern microprocessors |
|
The performance of a cache is close to that of SRAM
but at the cost of DRAM |
|
Caches can be used to form the basis of a parallel
computer |
|
Bus-based multiprocessors do not scale well: max
< 10 nodes |
|
Larger-scale shared-memory multiprocessors require
more complicated networks and protocols |
|
CC-NUMA is becoming popular since systems can be
built from commodity components (chips, boards, OSs) and use existing
software |
|
e.g. HP/Convex, Sequent, Data General, SGI, Sun,
IBM |
|

 Notes
Notes{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
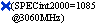{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
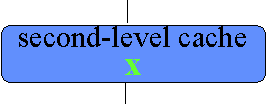{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
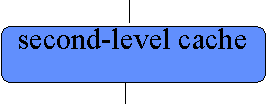{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
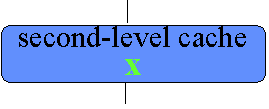{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
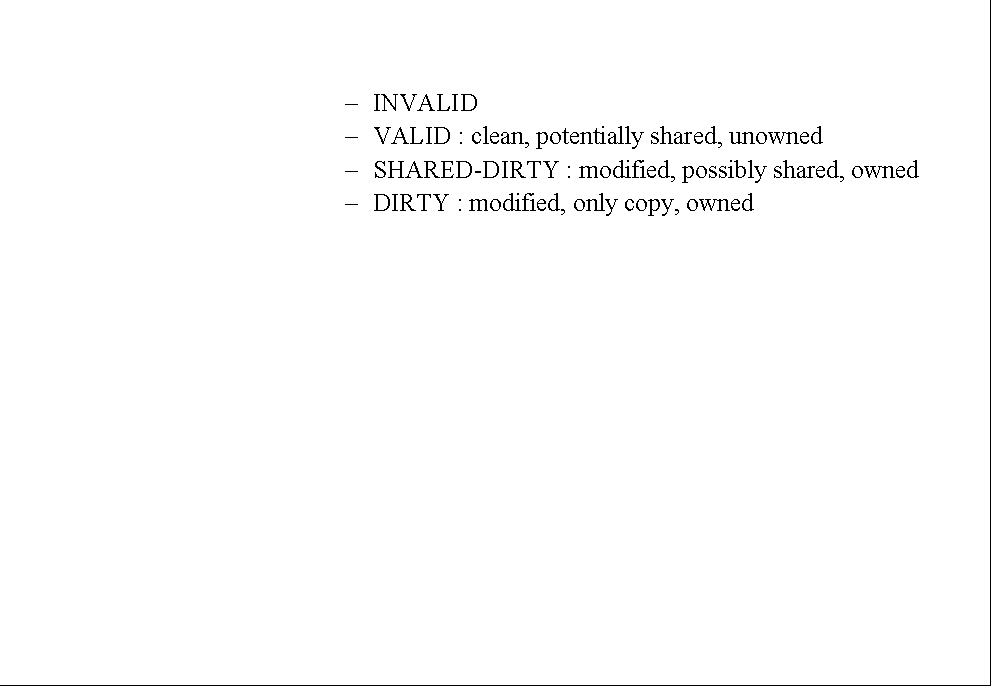{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
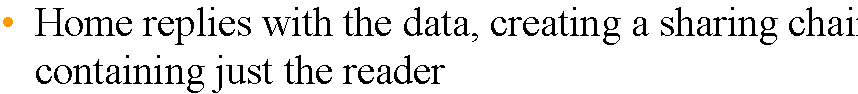{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}